
SDNS / GSLB direct-to-node: how it works, and when to use it for your object storage deployment
GSLB Published on •6 mins Last updated
There are a number of different load balancing options when it comes to optimizing your object storage environment. Given the range of options available, it is important to take a considered approach, carefully select the load balancing deployment method that is best suited to your unique traffic volumes, packet types and requirements.
The focus of this blog is on Global Server Load Balancing (GSLB) direct-to-node specifically — what it is, when to use it, and the pros and cons.
The throughput demands of object storage
We do a lot of work with object storage solution providers, and one of the main concerns they have is throughput. In other words, will the load balancer be able to cope with the needs and demands of the users? Our answer has always been "Yep!". We answer in the affirmative because we still haven't seen a workload that is consistently throughput constrained by the load balancer.
Despite the fact that we haven't yet come across a consistent 100Gbps workload, customers always ask for that kind of throughput. But what does that actually equate to? Well, let's go over the numbers:
| 100Gbps | Megabytes | Gigabytes | Terabytes | Petabytes |
|---|---|---|---|---|
| Second | 12,500 | 12.5 | 0.0125 | 0.0000125 |
| Minute | 750,000 | 750 | 0.75 | 0.00075 |
| Hour | 45,000,000 | 45,000 | 45 | 0.045 |
| Day | 1,080,000,000 | 1,080,000 | 1,080 | 1.08 |
Over a petabyte per day is far beyond the requirements of the majority of enterprises. That kind of throughput is Hyperscaler (AWS, Azure, etc.) territory for the most part.
100GbE is a commodity now though, right? On the one hand, 100GbE is much more common in the network core nowadays. However, on the other hand, it is not so common that every server has a 100GbE connection. And that's beside the point anyhow, because the servers that you are load balancing don't need to connect at 100Gbps! In fact, it is better that they aren't, as that would be a complete waste.
What do I mean by that? Well, load balancers should have a better connection than the real servers behind them. For example, a pool of five real servers with 10GbE NICs would need a load balancer with a 50GbE NIC for full throughput. So, if all real servers in that pool had 100GbE NICs you would need a 500GbE load balancer and 500GbE isn't a thing...
All that not withstanding, we are not (quite) arrogant enough to think that throughput constraint will never be an issue that we could face. That 100Gbps+ consistent workload is winging its way to us — it's only a matter of time. In fact, we are, and have, been working on solutions to this very problem with our products.
How? You might ask...Well, the main focus of our efforts in this regard has been on improving our Global Server Load Balancing offering. More specifically, on a particular implementation method we call Global Server Load Balancing (GSLB) direct-to-node; or SDNS for short.
What is SDNS / Global Server Load Balancing (GSLB) direct-to-node?
Global Server Load Balancing (GSLB) direct-to-node has the potential to be as fast as it is wordy (hence why the marketing team call it SDNS!). It removes the load balancer from the path of the load balancing, making it an ideal solution for unrestricted throughput.
At it's very core, SDNS is DNS round-robin with some health checks. That means that the load balancer is resolving DNS for requests to the server pool. However, that's not all it does. It is the following, additional functions that we've implemented that really sets SDNS apart:
1.Health checks: SDNS continually runs health checks against each of the servers in the pool. The health checks can be tailored to each installation to verify that the real servers are able to process requests correctly.
2.Dynamic weighting: The load balancer has the ability to dynamically weight the servers within a pool based on actual server performance to smooth distribution and alleviate hot nodes.
3.Topology distribution: With topology distribution you can distribute requests to nodes/clusters/datacentres preferentially based on where the request is coming from. Topologies are something that we use in our site affinity GSLB implementations and also something we can leverage in a SDNS installation.
How does SDNS / GSLB direct-to-node work?
Here's an illustration of how a SDNS implementation across two sites actually works:
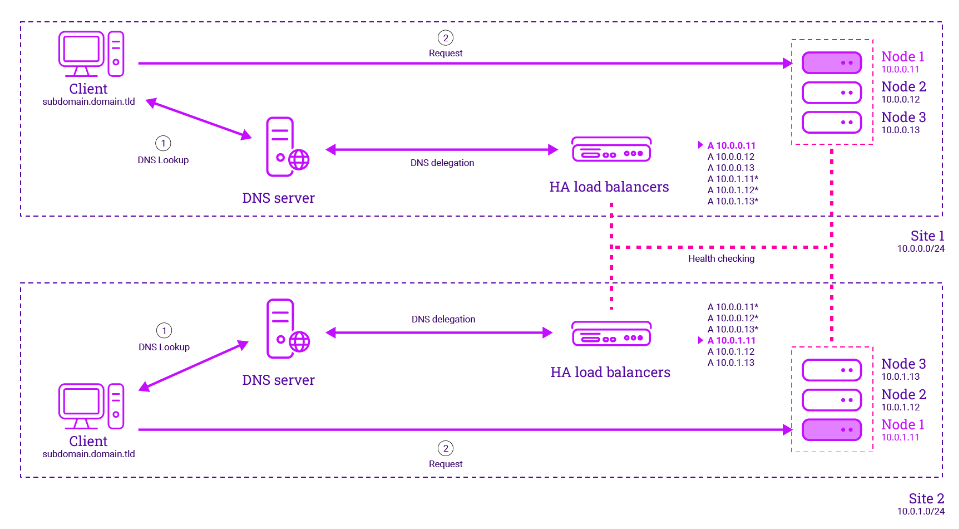
In a typical DNS Round-Robin deployment, requests are sent out to the configured nodes indiscriminately.
However, with SDNS, the real-servers undergo health checks to determine their availability. If a server responds correctly it is kept within the pool of available nodes for the load balancer to send requests to. If a server fails to respond correctly it is excluded from the pool of available nodes.
When should you use SDNS / GSLB direct-to-node?
Our standard method for object storage deployment uses Layer 7 Virtual Services to provide load balancing of the cluster. Layer 7 Virtual Services should always be used where possible, as it provides much better control, as I'll explain...
Possibly the greatest benefit of load balancing a storage cluster is its ability to even out the distribution of traffic, sending new connections to the storage nodes with the least active connections flattens the distribution of objects across the cluster. So proper load balancing is the preferred way to go — even at 88Gbps (11GB/s) you are able to exercise all of the controls that the appliance affords you. The load balancer is able to distribute connections based on your preference, maintain session persistency, manipulate headers, implements ACLs, etc. So, for most installations, it is more than enough to suit all your needs.
Virtual Services running on the load balancer provide the ability to have extremely granular control over the system functionality. Session persistence allows the ADC to always send requests to the same node or control/tune the persistence method to environment requirements. You also have a choice of distribution algorithms: weighted least connection or weighted round-robin. In each case you are able to adjust the node weighting to tune connection distribution.
Simply put, you should only use SDNS in extremely high throughput environments when your load balancer is no longer able to keep up with throughput.

What are the benefits of SDNS / GSLB direct-to-node?
Out of path
The overarching benefit that SDNS therefore provides is that it removes the load balancer from the traffic flow, meaning it is not bandwidth restricted.
Scalability
Direct-to-node is theoretically unlimited when it comes to scalability. However, it is not practical to have it stood up in front of a 1000 node cluster, as a 1000 node cluster is not a practical solution for the majority of use cases.
Preventing 'hot nodes'
Because the throughput for the cluster is only limited by the network, SDNS can prove useful for smoothing out utilization in object storage clusters with high node counts. It is not recommended for small clusters.
What are the limitations of SDNS / GSLB direct-to-node?
'Bursty' workloads
SDNS is mainly leveraging DNS to perform load balancing. That means you are somewhat at the mercy of DNS TTL and caching. This is a particular problem with 'bursty' workloads. If a whole load of requests come into the GSLB all at once, they are going to be resolved to just a few nodes. SDNS is best suited to consistent high throughput workloads. That is where it is able to smooth the distribution best.
Small clusters
It simply doesn't make sense to implement SDNS on small clusters. Clusters sized at less than 20 nodes would be far better served by regular load balancing.
Every object storage solution is different and each object storage implementation has it's unique requirements. So, you need a load balancing vendor who can tailor their deployment and work with you to provide a solution that is fit for purpose.
Traffic distribution
SDNS is not able to smooth traffic distribution as efficiently as Virtual Services which offer session persistence, faster Real Server health checking, better load distribution, and the ability to manipulate header information.
Conclusion
Layer 7 Virtual Services should always be your starting point when it comes to load balancing object storage nodes. However, in situations of extremely high throughput, which the load balancer cannot cope with, SDNS might be the next best thing.
For advice on the most suitable deployment for your particular object storage environment, speak to one of our technical experts.