










Choosing the best option to host across multiple locations or data centers
Organizations are moving away from the traditional data center model, and favoring a hybrid approach to hosting their systems and applications, that involves multiple sites, providers and even cloud environments.


When moving beyond a single availability zone, the primary challenge shifts from server health to traffic ingress management.
Multi-cloud and multi-site solutions must solve for the DNS caching problem, site-to-site latency, and manual intervention risks.
Here I evaluate the most effective methods for cross-site application delivery —including L3 fallback servers, Anycast routing, and why GSLB is more than just 'advanced DNS'.
What you'll learn:
- Architectural Trade-offs of L2 vs. L3 Connectivity: Understand the requirements for stretching a VLAN across sites to support Active-Passive HA pairs versus using L3 routing with fallback server configurations.
- GSLB vs. Traditional DNS: Learn why Global Server Load Balancing (GSLB) is superior to standard DNS round-robin, specifically regarding advanced health checking and proximity-based routing (Geo-LB).
- Implementing Anycast for Rapid Failover: Discover how BGP-based Anycast provides near-instantaneous switchover compared to DNS-based methods by advertising a single IP across multiple geographic nodes.
- The Mechanics of Cross-Site Failover: Deep dive into the role of Gratuitous ARP (GARP) in L2 extensions and how to mitigate client-side DNS caching issues during a site outage.
- Hybrid & Multi-Cloud Resiliency Patterns: Identify the best scenarios for integrating cloud-native load balancers (like AWS Route 53) with on-premise appliances to create a unified, high-availability architecture.
Multi-site and multi-cloud architecture options
Organizations are moving away from the traditional data center model, and favoring a hybrid approach to hosting their systems and applications, involving multiple sites, providers and/or cloud environments.
I'm going to cover a few scenarios below, and hopefully answer some common questions e.g.
- Can I support failover between data centers?
- Can I have the active load balancer at one site and the passive at another?
- Can I use Global Server Load Balancing (GSLB)?
Spoiler alert: the answer is 'yes' to all three. But there are other considerations...
- How are your DCs connected?
- What method should you use?
- Have you stretched your network/got a common IP space between sites?
Here are 6 different data hosting options to consider – but sadly no magic-bullet/one-size-fits-all answer....
Option 1. Content Delivery Networks (CDNs)
If you're running a public facing corporate website this is one of your best options! A CDN offers a wealth of features such as DDoS protection, caching and geo-redundancy, so will not only help to provide high availability but also protect your websites.
However, it's pretty useless for any internal applications – so, mostly CDNs use Anycast and DNS (very advanced GSLB solutions) as part of their products, on your behalf. You'll often be getting the benefits I mention below for these technologies. However, I always suggest that you talk to the vendor about what you're actually going to get. For example, I don't think Akamai offers an Anycast solution directly to customers, but obviously use it as part of their service – such as the DNS which will almost certainly be backed by an Anycast solution.
More information on Cloudflare CDN and Anycast.
Option 2. DNS
We actually have a few of options here...
We could simply switch the DNS by hand and use a short TTL – but that sucks, as it requires manual intervention. So then we automate it in some way: making a script to monitor our application, maybe utilising TSIG to update the entries much like those free dynamic DNS services. This sort of thing could be done from a real server or even the load balancer as part of a really cool health check! But this sucks too – just a lot less, and now it's a homebrew solution with all the issues that may come from that, not forgetting that you're in both scenarios relying on the client to perform another lookup... which it may not do straight away – or even at all. Caching the result it initially received
So, you could adopt an approach of returning several A records, which, in theory, should allow the client to cache all answers and try them in turn – until one works. However, this often leads to longer connections than usual, as clients try the bad answer(s), certainly it works for HTTP(S) traffic as a web browser shouldn't throw an error until it's attempted all the answers it received. At worst it might require a page refresh but as the bad address could still be tried, mileage may vary – especially with non-web traffic. Don't get me wrong: there are actually some pretty cool things you can do with your average DNS server, for example:
Microsoft DNS Load Balancing and Geo Location in Server 2016
(nearly a fully-blown internal GSLB!):
- docs.microsoft.com/en-us/windows-server/networking/dns/deploy/app-lb
- technet.microsoft.com/en-us/library/mt705726
Setting up secure dynamic updating of Windows DNS and linking with other systems:
This is common, and there are many ways to achieve this e.g.
Option 3. GSLB – more than just advanced DNS
The key difference between GSLB vs other DNS based solutions is proper health checking, and that it will usually offer additional benefits/gimmicks such as routing traffic preferentially to local servers, geo-load balancing to the closest geo location, or shortest round trip.
Like any DNS based solution, it's limited by either requiring the app to perform another DNS lookup or if you decide to serve multiple answers these could be cached by the application before they subsequently fail a health check.
However, it is automated and the best DNS based solution you can get so if nothing else should reduce potential support calls over other DNS based solutions especially if you also return multiple answers.
You can't get much better than the offerings supplied by NS1 and AWS (Route 53) if providing a public internet facing application, however, for internal, multi-site solutions, you may need to consider a GSLB appliance.
Route53, NS1 and Oracle DNS (formerly DynDNS):
- docs.aws.amazon.com/Route53/latest/DeveloperGuide/dns-failover
- ns1.com/dns-global-server-load-balancing
- oracle.com/cloud/networking/dns/
For more on GSLB, check out our comprehensive guide.
Option 4: LAN Extension
Some of our customers choose to stretch a subnet/VLAN over multiple locations.
As I mentioned above, you'll need a very good link between sites if you intend to run a pair of load balancers in high availability across it. You'll also need some high-end switch or router equipment, similar to what Cisco and other top end providers offer (unless you have access to dark fibre or some kind of L2 WAN for a physical link).
This option enables you to have an active load balancer in one location, with a passive in another, failing over the VIP address between sites using our built in HA – assuming link speed and reliability allows. Once you have the same subnet available on both sides, it's simple to setup: just pair the appliances as normal, but with one at each location.
To achieve this, you can use various solutions: a long cable between two buildings, to virtual network overlay solutions such as Cisco's OTV technology, which routes L2 networks over L3 connectivity.
Open source solutions exist as well, such as Open vSwitch.
Option 5: Anycast / Border Gateway Protocol (BGP)
Anycast is basically having the same IP address reachable on multiple nodes.
Different routers will advertise different paths that terminate in different locations, and you can also perform health checks (as with GSLB) – but it's far more complex to manage yourself, as it requires an understanding of BGP to achieve.
It's potentially the ultimate solution, certainly better than GSLB as it offers a much faster switchover on failure – hopefully invisible to users if the application isn't stateful. As mentioned above, many CDNs are already using this technology to help provide their services – one of the main reasons they're so good.
It was originally designed to make DNS servers highly available, but people are employing it more and more for websites and other TCP traffic.
Here's a good online explanation, a nice implementation example, Cloudflare's take, and a great, aggressive slideshow on Anycast and TCP.
Option 6: Additional load balancer in the cloud
One pretty cool solution for public facing applications is using a load balancer hosted in a big resilient cloud like AWS, there are costs involved in terms of hosting and data usage but it offers a near perfect solution otherwise for most scenarios as you can generally rely on Amazon's resilience and/or use two load balancers in separate availability zones to maximise HA. Or go nuts! Use two separate load balancers in two separate regions (or even cloud providers!) and combine GSLB in the form of Route53 in front...
Great! But which option is really the best? That depends; so let's focus on the following three scenarios.
Example 1. Layer 2 linked offices with clients in both locations and HA across sites:
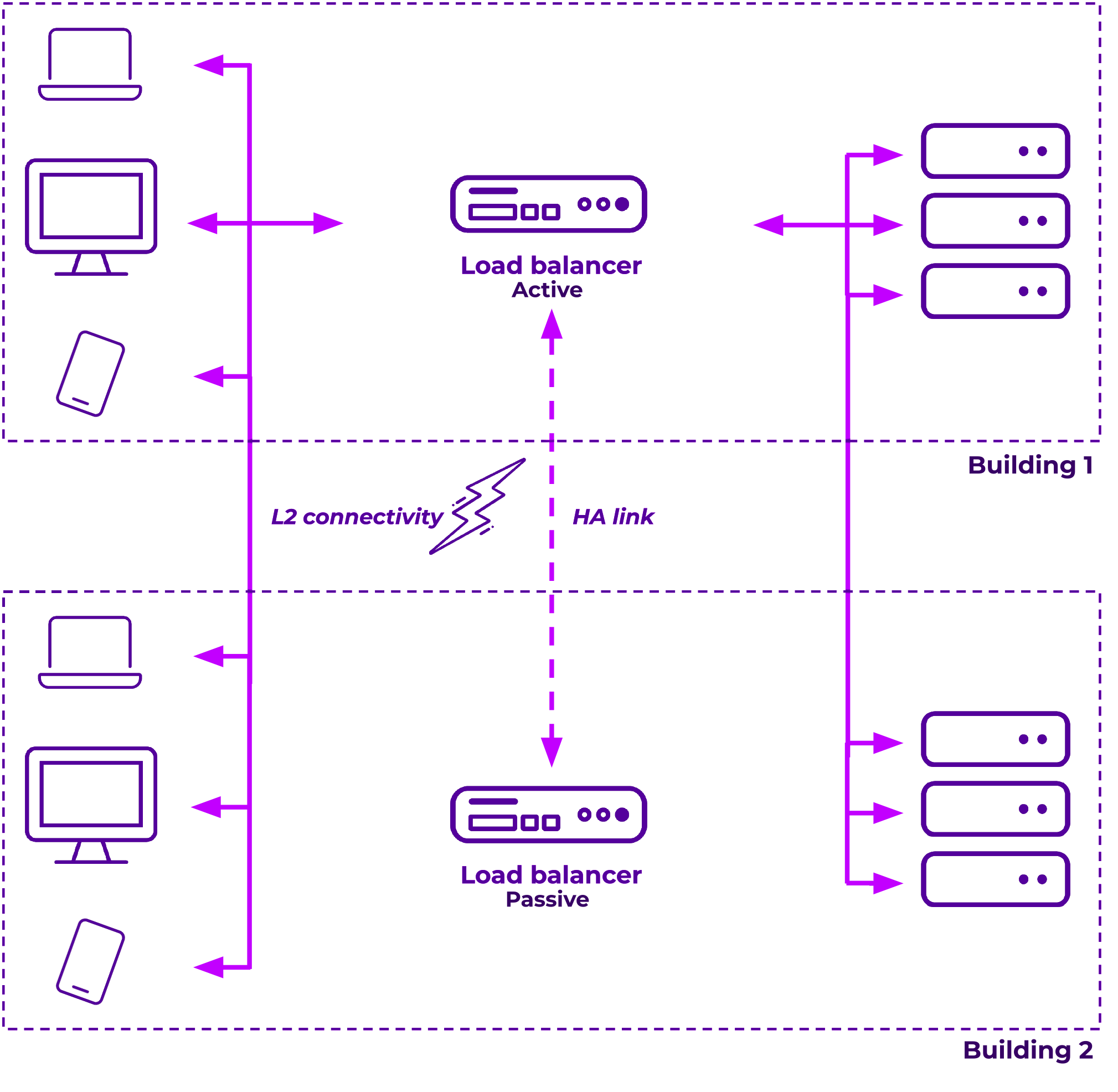
- This example can be achieved by providing a Layer 2 link, so extending the LAN across sites.
- This is the only option if you want to establish an active/passive pair between sites, so doesn't matter if it's sites linked with cables – or a more complex solution.
- You'll need to make sure that you have the same subnets at Layer 2 available on both sides. Failover is performed by a Gratuitous ARP (GARP) so MAC address resolution needs to work across sites.
Example 2. Multiple sites, Layer 3 linked offices with fallback to other site.
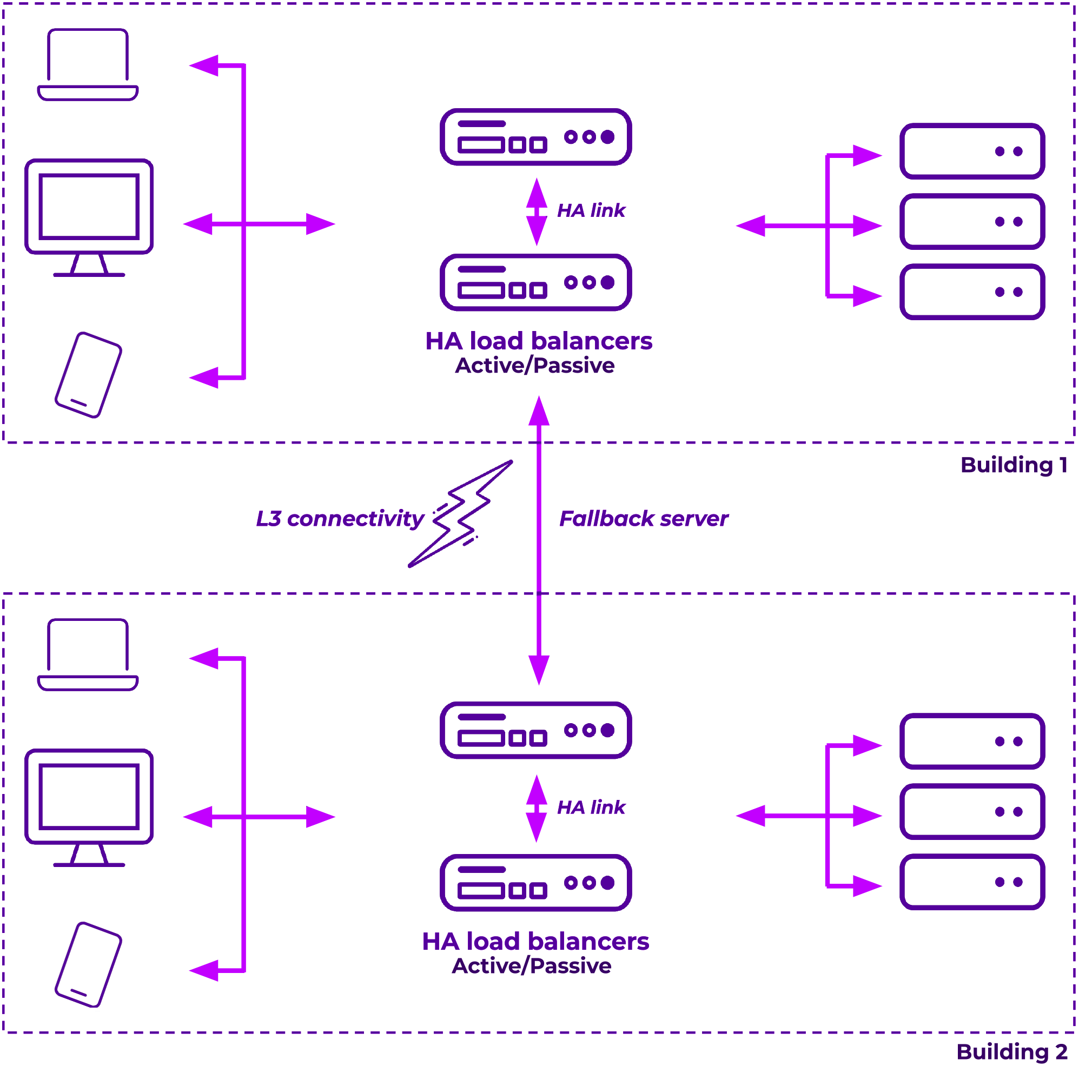
Here we can use multiple pairs for each site, we then utilise the fallback server to point each site to the other so that if all real servers fail health checks on one side the load balancer will use the other sides VIP as a real server until one of the local servers return.
But, this has the drawback of needing one of the pair of load balancers also still available during such an outage to serve the fallback server... so it doesn't necessarily work during a complete server room failure unless you also host the servers in multiple rooms or at the very least I'd suggest separate racks. However, most commonly a total server room failure means the site has also lost connectivity so this is usually enough for most. If, however, you do have the requirement to survive a local server room failure entirely you could also use a DNS solution in tandem so clients could then still lookup DNS on the other side and get the remote answer.
Example 3. Hybrid deployments with GSLB.
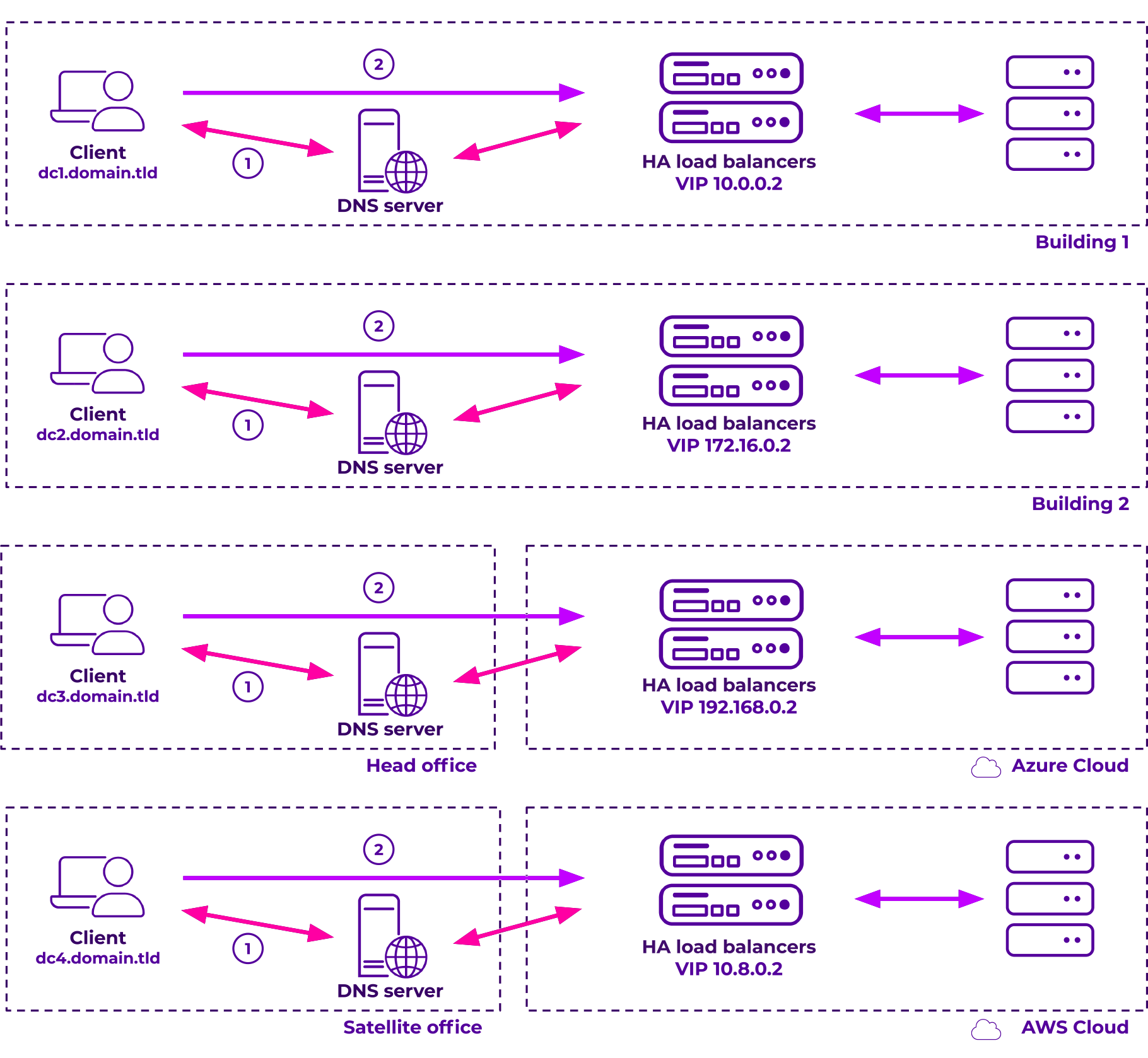
This would benefit from an on-premise GSLB load balancer or a cloud-based solution, if you're really looking for maximum availability and failover times. The cloud based load balancer offers advanced persistence types and potentially much better health checks.
Which option is best for multi-site or multi-cloud data hosting?
If considering Anycast then the easy option would be via a managed provider like Cloudflare, although for the more brave amongst us who can tackle their own BGP routing you might consider managing it yourself. For those with far simpler availability and failover requirements a robust, externally-hosted GSLB solution like Route 53 may suffice.
As I said at the start of this blog – there's no 'magic bullet'.
You'll need to choose which of these options will work best for you, and which compromises you're willing to make. You could decide that a manual DNS change is acceptable for your less critical applications – many people do! Or do you already have the equipment and in-house expertise needed to tackle a LAN extension or BGP solution yourselves? It's a tough choice, so it certainly depends on both the application as well as your organization.
When making such architectural decisions, I always suggest talking to the vendors involved – both with the load balancer provider, as well as the providers of your other network infrastructure – to see what options they can help you with.
And if any of the information above has left you with further questions, feel free to leave me a message below!
Why Loadbalancer.org for GSLB?
The Engineers' choice for smarter load balancing

Ensuring high availability of a Microsoft Exchange environment for a leading cloud provider



Related posts
ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB

What's the best cloud load balancer? AWS, Azure, GCP, Cloudflare, or a third-party alternative?
Multi-AZ resilience: Why the recent AWS outage shows you need it
How can I load balance UDP with open source HAProxy?

HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!
