











The rise of AI, high-performance computing (HPC), and massive unstructured data sets has completely transformed data storage architecture. Driven by this demand, enterprise storage giants like VAST Data and WEKA are delivering staggering levels of throughput and near-limitless scalability.
Whether it is VAST’s disaggregated shared-everything (DASE) architecture or WEKA’s blistering NVMe-tier parallel filesystem, these solutions share a fundamental reality: a storage system is only as fast as the front door that lets data in.
To prevent severe bottlenecks, a load balancer is essential in these environments. But once that’s decided, infrastructure teams then hit a major fork in the road:
- Leverage a lightweight open-source proxy like Envoy; or
- Deploy a dedicated enterprise load balancer.
While Envoy is certainly popular for cloud-native microservices, microservices are not designed for enterprise data storage. This detailed comparison explains why enterprise storage solutions require a dedicated, storage-optimized Loadbalancer.org appliance rather than an open-source Envoy proxy deployment.
Table of contents
- The Envoy Proxy sweet spot
- Why storage vendors need a purpose-built load balancer
- The core DNA challenge: Microservices vs. heavy storage
- Why Envoy falls short for modern storage architecture
- Where Loadbalancer.org delivers maximum storage optimization
The Envoy Proxy sweet spot
Where Envoy Proxy fits well
Envoy Proxy was designed primarily for microservices traffic management i.e. east-west communication, service discovery integration, retries, circuit breaking, and observability within Kubernetes and service mesh ecosystems.
That solution works really well when:
- Traffic is stateless HTTP/gRPC
- Workloads are short-lived services
- Failover decisions are application-layer and transient
- The platform is already Kubernetes-native
However, storage traffic is fundamentally different.
S3, NFS, and SMB workloads introduce characteristics that go beyond Envoy’s sweet spot:
- Long-lived connections (SMB sessions, NFS mounts)
- Stateful performance expectations
- Large payload transfers and streaming I/O
- Strict session consistency requirements
- Latency sensitivity at the storage layer, not just application layer
When Envoy is used as the primary High Availability (HA) and traffic distribution layer in these environments, storage vendors often encounter operational complexity rather than simplicity—particularly at scale.
The problem with stretching a service Proxy
When Envoy is repurposed as a front-door HA layer for storage systems, it typically ends up handling responsibilities such as:
- Load distribution across storage nodes
- Health checking of backend storage services
- Failover handling for persistent sessions
- TLS termination and re-encryption
- Traffic shaping for large object and file transfers
These are precisely the areas where load balancers (also known as Application Delivery Controllers) have decades of engineering maturity.
The challenge isn't that Envoy cannot perform these functions at a basic level— it’s that it was never optimized for sustained, high-throughput, state-aware storage traffic across multiple protocols simultaneously.
At scale, this can lead to:
- Increased operational overhead in tuning and maintaining configuration
- Complex failure modes during node or cluster events
- Limited visibility into storage-specific health metrics
- Challenges with SMB/NFS session persistence under failover
- Performance variability under heavy object storage workloads
Why storage vendors need a purpose-built load balancer
In contrast, a dedicated load balancer is purpose-built for Layer 4–7 challenges, offering deep protocol awareness and deterministic traffic control.
For storage vendors this matters because, at the enterprise level, the load balancer isn't just a traffic router—it's a critical component of the storage data path.
Key advantages for S3, NFS, and SMB environments
Whether you're managing object storage or traditional file shares, optimizing your delivery layer brings massive advantages.
1. Protocol-aware load balancing at scale
Purpose-built load balancers are specifically designed to handle:
- S3 API traffic (HTTP-based but high-throughput and stateless per request)
- NFS session persistence and export handling
- SMB connection state, session stickiness, and reconnection behaviour
This allows more deterministic routing decisions based on real backend state, in addition to standard service health probes.
2. True HA for stateful storage traffic
Storage systems don’t just need failover to survive a failure; they need one that hides the failure from the end user. In other words storage workflows need to keep data moving seamlessly during a disruption without dropping active connections, corrupting files, or forcing applications to restart.
A storage-aware load balancer can help ensure:
- Session persistence across node failures
- Controlled failover without client disruption (where possible)
- Health checks aligned with actual storage readiness (not just TCP/HTTP up/down)
This is especially important for SMB workloads, where session disruption can directly impact the user experience.
3. Full Layer 7 control beyond Kubernetes
While Envoy is strong inside Kubernetes environments, storage workloads often exist:
- On bare metal clusters
- In hybrid cloud deployments
- Across multi-site architectures
A dedicated load balancer provides:
- Advanced L7 routing rules across non-Kubernetes environments
- Content switching and header-based routing for S3 APIs
- Granular traffic policies independent of service mesh constraints
4. Global Server Load Balancing (GSLB)
Modern storage architectures increasingly span multiple sites for:
- DR (disaster recovery)
- Geo-locality
- Active-active object storage replication
With built-in GSLB capabilities, a dedicated load balancer enables:
- DNS-based and intelligent geo-routing
- Site-level health awareness
- Automated failover between datacentres
- Latency-based routing for optimal performance
This is an area where Envoy typically requires additional tooling and external systems to achieve equivalent capability.
5. Operational simplicity and deterministic behaviour
Storage teams value predictability over abstraction.
A dedicated load balancer provides:
- Clear separation between control plane and data plane
- Predictable failover behaviour
- Reduced dependency chains (no service mesh requirement)
- Easier troubleshooting at the network and storage boundary
The core DNA challenge: Microservices vs. heavy storage
To understand the operational mismatch, you must look at what these tools were built to do.
Envoy Proxy
Developed by Lyft, Envoy was fundamentally engineered as an edge and service proxy for cloud-native microservices. It is designed to handle millions of tiny, rapid HTTP/gRPC API calls between web containers. It excels at service discovery, dynamic routing, and complex container mesh topologies.
Loadbalancer.org
A dedicated load balancer like Loadbalancer.org's Enterprise appliance is purpose-built for massive data throughput, raw protocol survival, and storage vendor integration. It focuses on sustained, high-bandwidth workloads, handling gigantic payloads (like S3 multi-part uploads or large file blocks) without choking on memory or dropping connections.
Detailed architectural comparison
Here's a side-by-side comparison of the two solutions:
| Feature | Envoy Proxy | Loadbalancer.org |
|---|---|---|
| Primary design intent | L7 microservices, container service meshes (gRPC/HTTP). | High-throughput enterprise storage, S3 object API, NAS. |
| Throughput & scalability | Bound by host OS tuning; prone to memory spikes under large payloads. | N+1 scaling architecture built for > 1Tbps throughput with zero-copy data paths. |
| S3 optimization | Requires custom, complex Lua scripts or manual filters for S3 headers. | Native S3 optimization (e.g., Content-Length parsing for small/large object routing). |
| DNS & failover layer | Requires external tooling (CoreDNS/Consul) for geo-routing. | Built-in Smart GSLB with active topology awareness and True Zero-TTL. |
| Node telemetry | Basic HTTP/TCP health checks; lacks deep storage state monitoring. | Custom storage-layer feedback agents avoiding the hot node problem. |
| Management & support | Do-it-yourself CLI/YAML; strictly community or paid consulting support. | Dedicated UI/API storage portal with 24/7/365 storage-expert support. |
Why Envoy falls short for modern storage architecture
1. Large object vs. small object throughput considerations
- Envoy handles connection streams efficiently, but it is highly sensitive to memory utilization when processing deep buffers. In object storage workloads clients simultaneously push multi-gigabyte files.
- Loadbalancer.org uses an enterprise-hardened operating kernel tuned for efficient data paths, allowing it to sustain high parallel throughput across clusters while reducing the risk of memory pressure under heavy load. While Envoy’s internal buffer architectures can experience heavy memory fragmentation when mixed workloads hit simultaneously.
2. The S3 protocol nuance
S3 is not just standard HTTP. It relies heavily on specific metadata headers, signed payloads (AWS Signature V4), and chunked multi-part uploads.
- Envoy views S3 traffic as generic HTTP/1.1 or HTTP/2. If you want Envoy to act intelligently based on an S3 payload—such as analyzing the Content-Length header to route tiny, high-I/O objects to flash-optimized tiers and massive objects to archival tiers—you have to write, test, and maintain custom Lua filters.
- Loadbalancer.org features out-of-the-box storage profiles that natively parse object storage payloads, reducing the configuration burden from the storage engineering team.
3. Storage-aware health checks and the hot node problem
If a single VAST CNode or a WEKA S3 container slows down under a heavy internal rebuild or metadata synchronization task, a standard HTTP health check might still report it as 200 OK.
- Envoy will continue to send traffic to that node, potentially creating a hot node that drags down the performance of the entire parallel filesystem.
- Loadbalancer.org utilizes customized, lightweight Feedback Agents that monitor active system telemetry on the storage nodes themselves. If a backend node spikes in latency or CPU utilization, the load balancer dynamically throttles traffic before the node fails.
Where Loadbalancer.org delivers maximum storage optimization
While Envoy simply routes traffic, Loadbalancer.org is uniquely tuned to eliminate bottlenecks and guarantee seamless data paths across complex storage architectures:
1. Seamless integration with VAST DNS and VIP pools
One of VAST Data’s greatest strengths is its disaggregated architecture, allowing performance scaling by adding CNodes. VAST uses its own embedded DNS server and Virtual IP (VIP) pools to move IPs seamlessly between nodes during failures or upgrades.
Loadbalancer.org integrates seamlessly with this design. Rather than fighting VAST’s internal VIP failovers, Loadbalancer.org complements it by handling heavy external North-South S3/NAS traffic distribution, ensuring clients never pin to an isolated VIP during cluster upgrades.
2. Multi-site synchronization and smart GSLB for WEKA
For multi-region cloud storage deployments or active-active hybrid WEKA clusters spanning multiple data centers, site routing is critical.
Loadbalancer.org features a built-in Global Server Load Balancing (GSLB) engine straight out-of-the-box, as standard. This can be utilized in a number of ways, as shown in this example:
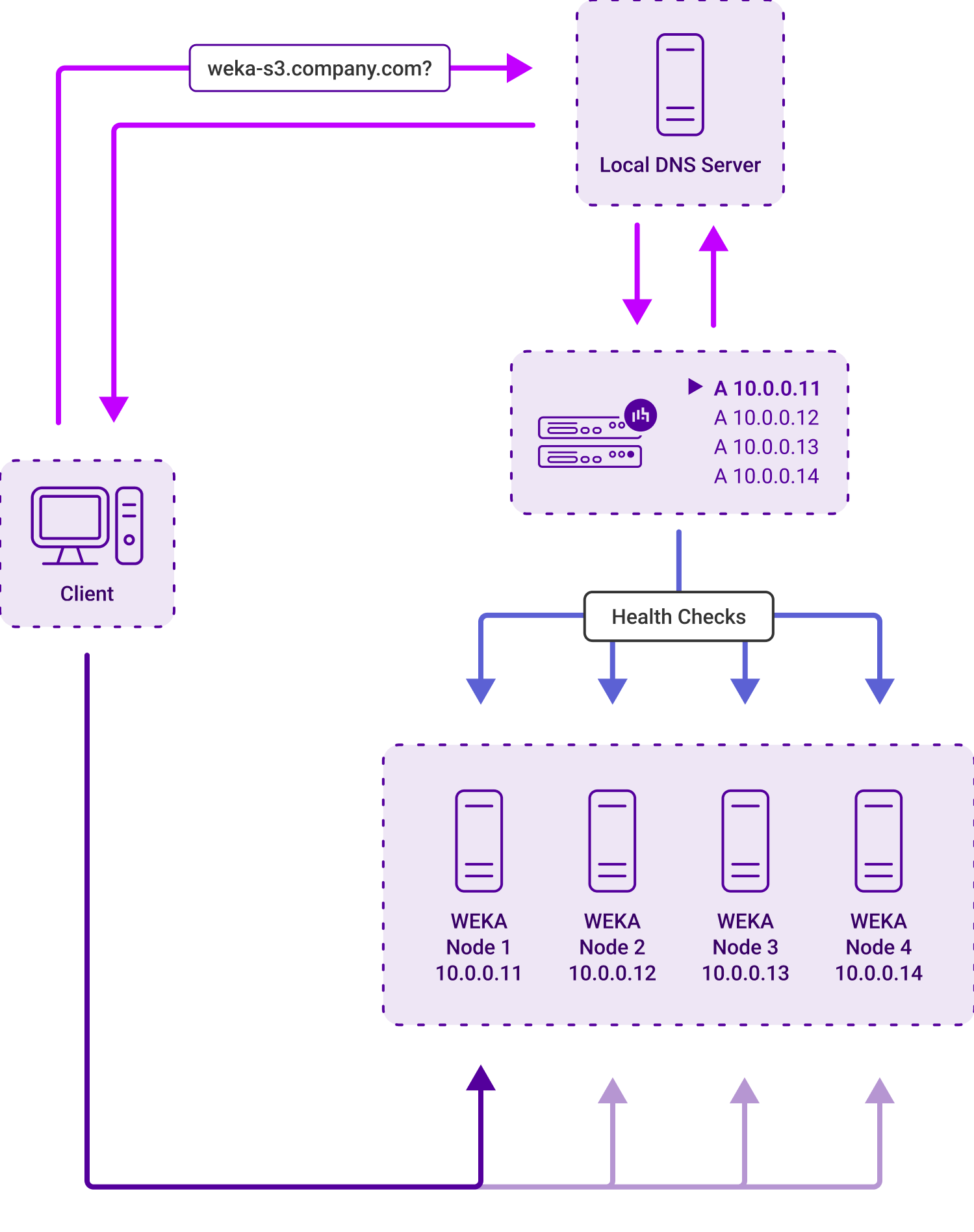
This brings two major advantages over Envoy:
- Topology-based routing: Ensures high-performance client traffic stays local to the nearest storage cluster, avoiding cross-site latency penalties.
- DNS TTL flexibility: Supports Zero-TTL DNS responses to minimise caching and reduce failover delays, while also allowing higher TTL values when required.
In practice, some storage vendors (including VAST) recommend using TTL=1 in DNS because certain clients and recursive resolvers do not handle TTL=0 correctly. Loadbalancer.org supports both approaches, giving teams flexibility to tune DNS behaviour based on their environment.
3. Overcoming enterprise maintenance & compliance headaches
Deploying Envoy means managing raw, complex YAML files, orchestration hooks, and manual SSL/TLS certificate distribution across multiple proxy servers. For enterprise environments supporting mission-critical storage, this introduces significant operational risk.
Loadbalancer.org’s intuitive Enterprise WebUI is designed for engineers, by engineers, making maintenance much easier and reducing the risk of human error. And with detailed step-by-step documentation and a consultative support team to help you solve problems faster, you don’t have to be a load balancing expert to see a difference in minutes.
Furthermore, integrating Loadbalancer.org’s Enterprise load balancer with the ADC Portal centralizes your entire load balancer estate, reinforcing compliance frameworks like SOC 2, ISO 27001, and HIPAA. While managing fragmented load balancers across hybrid and multi-cloud environments typically introduces risks—like human error, unpatched vulnerabilities, or expired certificates—the ADC Portal eliminates these blind spots. It is purpose-built to maximize visibility, boost operational efficiency, and harden your compliance posture.
Conclusion
As object and file storage evolves into a core platform service (especially for AI, analytics, and hybrid cloud), the traffic layer becomes critical infrastructure — not just plumbing.
The limitations of an adapted microservices proxy
Reliably using open-source Envoy Proxy typically means depending on community support or internal resources when production issues appear. When petabytes of vital AI training data or backup pipelines stall, troubleshooting via GitHub is an unacceptable risk for many enterprises.
Architecturally, Envoy ties storage availability closely to application delivery patterns and service mesh tooling, which can constrain scalability in some deployments. Yes, Envoy is a great microservices proxy, but it is not a purpose-built enterprise storage load balancer. For S3, NFS, and SMB environments where performance and continuity are vital, Loadbalancer.org provides a more scalable, deterministic approach.
The benefits of using a purpose-built load balancer
Decoupling storage HA from service mesh complexity gives vendors a cleaner path to high resilience, simpler operations, consistent performance, and true multi-site global load balancing.
Loadbalancer.org delivers this through enterprise-grade appliances paired with direct access to specialized storage-networking engineers. With deep expertise in the S3 protocol, VAST VIP behaviors, and WEKA’s parallel NVMe pipelines, they help ensure high-performance storage solutions remain stable under intense production workloads.
Further reading
- How to load balance Weka for optimum performance
- Load balancing Weka is no longer optional — the new normal is 100X faster
- How to to use content-length headers to solve the small objects problem
- The ultimate guide to Global Server Load Balancing
Optimize your storage workflow
Discover Loadbalancer Enterprise

Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB


Loadbalancer.org announces leadership transition and next phase of growth
Related posts
Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB
How to load balance a MariaDB Galera Cluster for performance and HA using LVS & Ldirectord

Optimizing data storage: Using content-length headers to solve the 'small objects problem'
Load balancing Weka is no longer optional — the new normal is 100X faster

HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!