












Recognising a critical challenge in enterprise data architecture—separating data availability from data accessibility—HPE reached out directly to Loadbalancer.org to co-architect a unified solution. By combining the HPE Alletra Storage MP X10000 (HPE X10K) object storage platform with Loadbalancer's Global Server Load Balancing (GSLB) technology, this collaborative engineering addresses a crucial gap.
While HPE X10K ensures that object data is resilient, highly performant, and synchronized across clusters, a dedicated load balancer is needed to ensure that clients can actually reach the optimal storage node without hitting a bottleneck, experiencing high latency, or dropping connections during a site outage.
By combining the two technologies, and placing the fully qualified domain names (FQDN) of enterprise S3 buckets under the purview of Loadbalancer.org, storage traffic is no longer left to chance. Users can be intelligently steered to the optimal HPE X10K cluster site based on real-time health, proximity, and network performance—ensuring multi-site high availability that keeps pace with modern enterprise data demands.
The HPE-validated architecture
HPE Alletra Storage MP X10000 object storage
The HPE X10K, engineered to handle massive, unstructured S3 object storage workloads with high resiliency. This is architecture built for exabyte scale, where keeping vast data buckets fast, perfectly synchronized, and constantly available across multiple geographical locations is paramount.
Loadbalancer.org GSLB
Loadbalancer.org’s smart Global Server Load Balancing (GSLB) uses real-time data and site-specific topology to intelligently route traffic, meaning it understands how your infrastructure is configured, as well as where your applications and users are located. This is critical for workflows that need unrestricted bandwidth, such as object storage and AI. The result is supercharged enterprise-applications with seamless multi-site failure if things go wrong.
The HPE end goal: a unified solution for their customers
Without Global Server Load Balancing (GSLB) in place, multi-site traffic distribution is often limited. Storage architects are forced to rely on basic round-robin DNS or a rigid active-passive model—where one data center handles the primary storage workload while another sits idle as a hot standby, waiting for a catastrophic infrastructure or network failure to trigger a manual switchover.
HPE's product team were acutely aware of this, and worked directly with Loadbalancer.org to utilize context like source IP awareness or network response measurements via the Client Subnet (EDNS0) extension to guide storage traffic to the best possible landing site.
The end goal was to facilitate multi-site failover and asynchronous replication of HPE X10K nodes across multiple data centers for HPE customers.
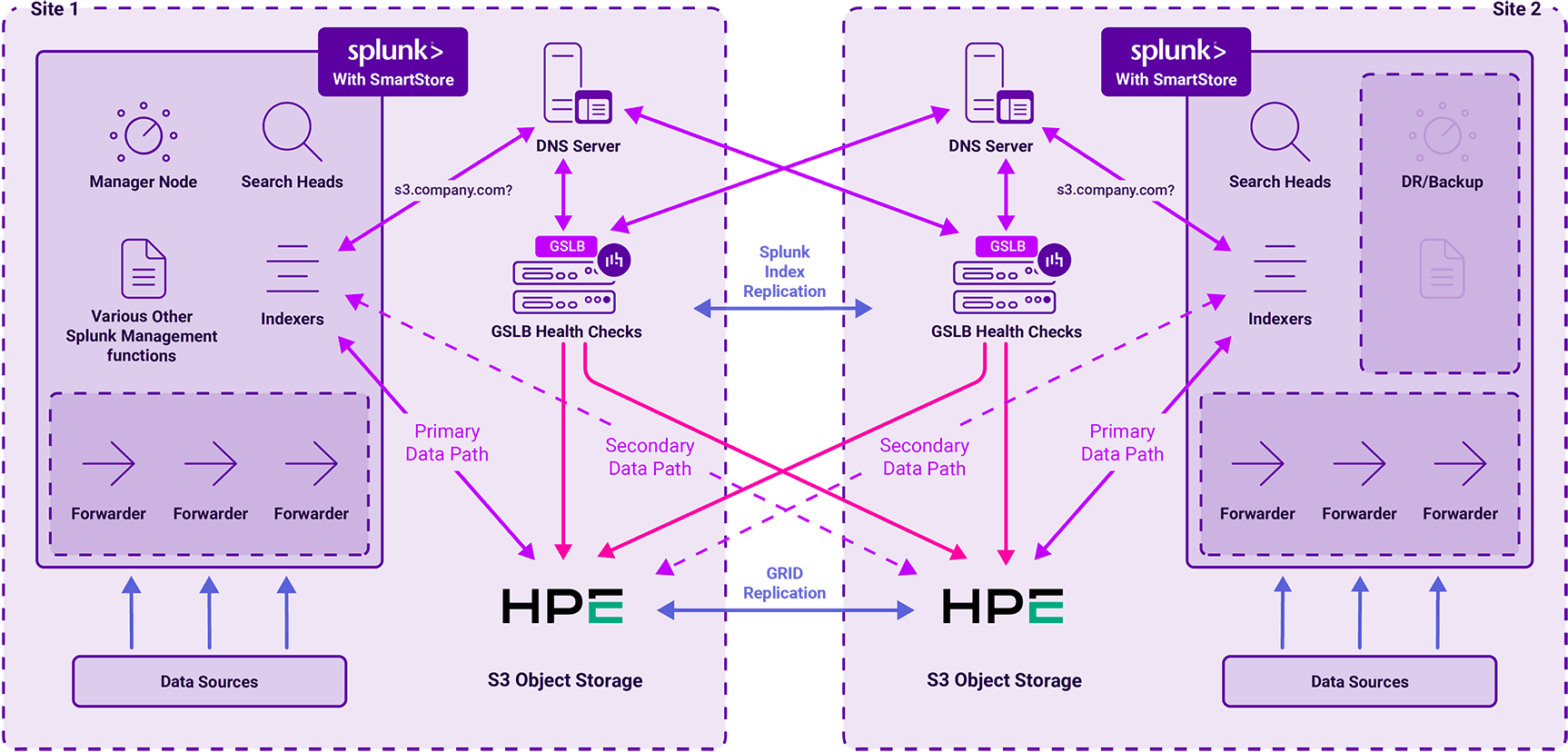
The lab setup
To demonstrate this capability, a joint team from Loadbalancer.org and HPE spun up a feasibility and integration validation environment.
The baseline setup for the lab environment was structured as follows:
- The use case: Multisite Splunk
- The storage layer: HPE Alletra X10000 storage platform for S3, NFS and SMB.
- The GSLB infrastructure: Loadbalancer.org virtual appliances deployed as VMs within an enterprise ESX server environment.
- The topology: A multi-member GSLB topology focused heavily on verifying global steering, automated failover/failback, and granular DNS redirection.
GSLB storage infrastructure setup
To hit on the main administrative tasks, the virtual ADCs must be strategically aligned within the network path to act as the authoritative voice for routing clients to the storage nodes. The following technical hurdles and insights outline how the joint engineering teams moved this setup from concept to validation.
1. Scaling the GSLB configuration via CLI
During initial setup, the HPE team requested programmatic guidance on mapping existing infrastructure into the GSLB configuration framework.
Rather than walking through repetitive web-UI configurations for bulk object storage members, programmatic scalability was achieved via the Loadbalancer.org CLI tool. Using lbcli, administrative teams can easily automate the inclusion of vast node groups. For example, adding multiple cluster members to an existing site mapping can be condensed into a basic bash loop executing administrative calls.
This ensures that as storage buckets or nodes dynamically scale out on the HPE X10K side, the delivery controller can keep pace automatically.
2. Solving the DNS delegation & FQDN mismatch cog
The critical cog in the wheel for any global traffic management deployment is proper DNS routing. Early in the testing phase, the team hit a bottleneck: an nslookup targeted at the storage endpoint uniquely returned the root IP address of the load balancer itself, instead of successfully distributing the targeted IPs of individual GSLB members.
The root cause was isolated by Denney and Gaurav to a corporate DNS mismatch. In any active GSLB setup, the main corporate DNS must accurately delegate a dedicated subdomain to the load balancers so that they can act as the authoritative name servers for that zone. This simply means adding an NS record in your DNS server that points to the load balancer's IP address or FQDN.
The Fix: The lab team isolated the infrastructure by configuring a specific storage subdomain zone: gslb.ftc.storage.hpecorp.net
Once the fully qualified domain names (FQDN) on the Loadbalancer.org appliances were updated to tightly match this delegated subdomain, the system began properly intercepting queries and intelligently serving the distinct backend IPs of the corresponding HPE X10K cluster sites.
3. Contextual optimization with EDNS0
To take things one step further, Damian from the Loadbalancer.org architecture team validated the final config with an important architectural reminder: ensuring the enablement of the EDNS0 (Extension Mechanisms for DNS) Client Subnet extension within the global DNS servers.
When a client queries a storage cluster endpoint via an upstream corporate DNS resolver, the load balancer normally only sees the IP address of the resolver, not the actual end-user or storage client. By ensuring EDNS0 is actively enabled, the resolver passes along the client’s original subnet information. This allows the Loadbalancer.org ADC to make highly accurate topology routing decisions, ensuring data traffic lands on the topologically closest or lowest-latency HPE X10K node.
The power of jointly validated architecture
The successful validation of this architecture provides enterprise environments with a pre-tested, dependable blueprint for multi-site high availability across object and file storage.
By combining HPE Alletra X10000’s native data resilience with Loadbalancer.org’s intelligent traffic steering, storage architects can deploy with confidence, knowing the major integration and failover hurdles have already been cleared.
Key deployment takeaways
For architects replicating this validated environment across multiple data centers, keep these core operational lessons in mind to maximize the benefits of the joint solution:
- Zone consistency matters: Ensure your internal DNS delegation zones and your ADC's FQDN settings are completely unified under the designated GSLB subdomain (e.g., gslb.yourstorage.domain.com).
- Leverage CLI for scalability: Avoid relying solely on UI operations when mapping large storage node pools. Utilizing automated lbcli scripting significantly accelerates data center expansion and reduces human error.
- Enable EDNS0 at the Edge: Without Client Subnet context, geographic and latency-based traffic steering reverts to guessing based on resolver locations. Enabling EDNS0 ensures traffic is routed based on the actual location of the storage consumer.
The bottom line
You don't have to engineer multi-site failover and asynchronous replication from scratch. This joint validation proves that HPE and Loadbalancer.org work seamlessly together, paving a smooth, de-risked path for your production deployments.
Don't let traffic delivery hold you back
Get in touch to co-architect a unified solution

Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!


ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Related posts
ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB
How to load balance a MariaDB Galera Cluster for performance and HA using LVS & Ldirectord
Optimizing data storage: Using content-length headers to solve the 'small objects problem'
Load balancing Weka is no longer optional — the new normal is 100X faster
HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!