










Does the new multi-threaded support in HAProxy finally solve the 10G problem?
It’s no big secret that a single processor can only handle so much processing in a given time. So what happens when you reach the limits of what a single processor can handle? Simple, you add more processors.


The best thing about HAProxy is its single process event-driven architecture. It gives amazing performance in most real world scenarios and happily saturates gigabit + networks...
But the single process design is also the worst thing about HAProxy, because until now the way of scaling to 10G+ has been to use multi-process mode — which while incredibly fast... doesn't allow you to share advanced functionality such as stick tables between the processes (which sucks!)
20 Cores won't help you if HAProxy is only using one of them:
2 x Intel Xeon E5-2630 10 core 2.2Ghz
HAProxy handling 700TPS with 512KB packet size at 3GBits/s.
TSO & GRO disabled (which would give approx 40% boost if enabled).
Luckily Willy Tarreau and the HAProxy development team are geniuses, and after several years of hard work not only have they given HAProxy a multi-threaded mode... But they've even managed to keep the event driven architecture — with a scheduler in each thread. My brain can't quite wrap around how difficult that would have been, but the result is damn near perfect.
So what are my options for scaling HAProxy?
It’s no big secret that a single processor can only handle so much processing in a given time. So what happens when you reach the limits of what a single processor can handle? Simple, you add more processors.
How does this equate in HAProxy? Well, we have four modes we can call HAProxy in.
Single process mode - This is the ‘classic’ mode, a single process is created which handles all the transactions for HAProxy. Simple but limited in what it can handle (as you’ll see later).
Multi-process mode - Multiprocessing is adding more number of or CPUs/processors to the system which increases the computing speed of the system.
Multi-thread mode - Multithreading is allowing a process to create more threads which increase the responsiveness of the system.
Difference between Multiprocessing and Multithreading
Combination mode - A mixture of multi-process and multi-thread mode where you get X processes with Y threads per process.
Baseline analysis
Before we can perform any form of comparison, we need to ascertain what we’re doing a comparison against. I decided to use ‘iPerf’ as it’s (fairly) simple to use and does what is needed.
I set up a test lab using 3 old Dell R210 servers, all equipped with new dual port Intel 10gb NICs.
The iPerf client and server were both installed with Debian 9 (stretch) and updated packages prior to test. The HAProxy system was configured with 3 NICs, one on each of client, server and management networks. The client and server networks used the dual port 10Gb Intel card whereas the management used the built in broadcom 1Gb.
[Iperf Client] <---> [HAProxy] <---> [Iperf Server]
As iPerf, by default, uses TCP port 5001 I setup a Layer 7 service listener directed to a single iPerf server and disabled the service health checks.
listen IPerf10
bind 10.0.1.10:5001 transparent
mode tcp
option abortonclose
server Real1 10.0.1.11:5001 weight 100
On the iPerf client, I ran;
$ iperf -c 10.0.1.10 -t 300 -P 1
- c means “run as client mode, with the following as your server”
- t means “number of seconds to run” (time)
- P is “number of concurrent connections” (number of parallel jobs)
I chose a 5 minute (300 second) run so that it would give a chance for the traffic to settle without taking too long. I also chose a single connection as a base starting point.
The result of this was;
------------------------------------------------------------
Client connecting to 10.0.1.10, TCP port 5001
TCP window size: 85.0 KByte (default)
------------------------------------------------------------
[ 3] local 10.0.1.2 port 60282 connected with 10.0.1.10 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-300.0 sec 116 GBytes 3.32 Gbits/sec
3.32 Gbits/sec
I then decided I would see what happens if I increased the number of concurrent connections to 4.
------------------------------------------------------------
Client connecting to 10.0.1.10, TCP port 5001
TCP window size: 85.0 KByte (default)
------------------------------------------------------------
[ 5] local 10.0.1.2 port 60290 connected with 10.0.1.10 port 5001
[ 3] local 10.0.1.2 port 60286 connected with 10.0.1.10 port 5001
[ 4] local 10.0.1.2 port 60284 connected with 10.0.1.10 port 5001
[ 6] local 10.0.1.2 port 60288 connected with 10.0.1.10 port 5001
[ ID] Interval Transfer Bandwidth
[ 5] 0.0-300.0 sec 30.4 GBytes 871 Mbits/sec
[ 3] 0.0-300.0 sec 30.4 GBytes 871 Mbits/sec
[ 4] 0.0-300.0 sec 30.4 GBytes 871 Mbits/sec
[ 6] 0.0-300.0 sec 30.4 GBytes 871 Mbits/sec
[SUM] 0.0-300.0 sec 122 GBytes 3.48 Gbits/sec
3.48 Gbits/sec - Not a massive improvement in the grand scheme of things.
I also tried with 8 concurrent connections and that also made very little difference.
Time to try some changes in HAProxy...
Multi-process mode
Caveat 1: multi-process mode does not support synchronizing stick tables over multiple processes so each process will have it's own making it useless for persistence. However, HTTP cookies are supported so some persistence options do exist.
Caveat 2: multi-process mode means the stats page only displays one process per port, and requires additional config to show the different process stats
Required configuration changes;
‘global’ section;
Add “nbproc X” where X is an integer reflecting the number of processes you want to start.
for example;
global
daemon
stats socket /var/run/haproxy.stat mode 600 level admin
pidfile /var/run/haproxy.pid
maxconn 40000
nbproc 4
Multi-thread mode
Required configuration changes;
‘global’ section;
Add “nbthread Y” where Y is an integer reflecting the number of threads you want to start.
for example;
global
daemon
stats socket /var/run/haproxy.stat mode 600 level admin
pidfile /var/run/haproxy.pid
maxconn 40000
nbproc 1
nbthread 4
No other changes are needed to other sections.
iPerf Results
| Processes | Threads | Concurrent Connections | Throughput (Gbit/sec) |
|---|---|---|---|
| 1 | 1 | 1 | 3.32 |
| 1 | 1 | 4 | 3.48 |
| 4 | 1 | 4 | 8.03 |
| 4 | 1 | 8 | 7.93 |
| 4 | 1 | 16 | 8.64 |
| 8 | 1 | 4 | 6.14 |
| 8 | 1 | 8 | 9.35 |
| 8 | 1 | 16 | 9.39 |
| 16 | 1 | 4 | 6.13 |
| 16 | 1 | 8 | 9.38 |
| 16 | 1 | 16 | 9.31 |
| 1 | 4 | 4 | 6.07 |
| 1 | 4 | 8 | 8.07 |
| 1 | 4 | 16 | 8.07 |
| 1 | 8 | 4 | 3.55 |
| 1 | 8 | 8 | 9.22 |
| 1 | 8 | 16 | 9.20 |
| 1 | 16 | 4 | 3.15 |
| 1 | 16 | 8 | 9.15 |
| 1 | 16 | 16 | 9.08 |
| 2 | 2 | 4 | 6.40 |
| 2 | 2 | 8 | 9.10 |
| 2 | 2 | 16 | 8.02 |
| 4 | 2 | 4 | 8.15 |
| 4 | 2 | 8 | 9.32 |
| 4 | 2 | 16 | 9.17 |
| 8 | 2 | 4 | 6.17 |
| 8 | 2 | 8 | 8.96 |
| 8 | 2 | 16 | 9.14 |
| 2 | 4 | 4 | 8.00 |
| 2 | 4 | 8 | 9.00 |
| 2 | 4 | 16 | 9.11 |
| 4 | 4 | 4 | 6.11 |
| 4 | 4 | 8 | 9.31 |
| 4 | 4 | 16 | 9.15 |
Conclusion
A single, non threaded, process of HAProxy can handle a throughput of 3.32GBit/sec, which is fine unless you have 10GBit NICs, at that point the more threads and processes you can throw at it, within reason, the better. You need to be mindful that the rest of the system also need processor time to continue functioning. When using multiple processes you lose the ability to use session persistence and the stats require some ugly additional config. Multiple threads, however, has most of the advantage of multiple processes (goes faster) but without the drawbacks outlined above.
I feel it's also important to highlight that this was purely a 'maximum throughput/saturation test', further testing will be conducted which will include 'ramp testing' (start small and work up) as well as longer test runs and differing payload size tests.
Test system
Software:
HAProxy v1.9-dev0-929b52d-247 (git build)
iPerf v2.0.9 (from Debian 'stable' repository)
iPerf client and iPerf server systems built using Debian GNU/Linux stable.
Hardware:
Manufacturer: Dell Inc.
Product Name: PowerEdge R210
CPU: Intel(R) Xeon(R) CPU X3430 @ 2.40GHz
RAM: 2Gb DDR3 1333MHz
NIC: Intel Corporation Ethernet Controller 10-Gigabit X540-AT2 (Dual port)
I intentionally used legacy hardware (approx. 9 years old) to highlight the problem of a low clock speed when using single process mode.
If anyone is interested the hardware specification for our hardware load balancer — The Loadbalancer.org Enterprise R20 CPU is E3-1230v5 @ 3.40GHz (and has been for the last 3 years.)
Coming soon...
Shortly I will do some proper testing with a Spirent Avalanche for all sorts of different packet sizes, to get a more realistic benchmark of real world scenarios.
That's if we can stop Mark the development manager playing with his new and very expensive toy...
Really soon...
Mark has moved on to playing with 40G switches and cards. So he's finally let me get my greasy hands on the 10G Spirent. It's been a bit of a learning curve for me with a lot of strange initial results:
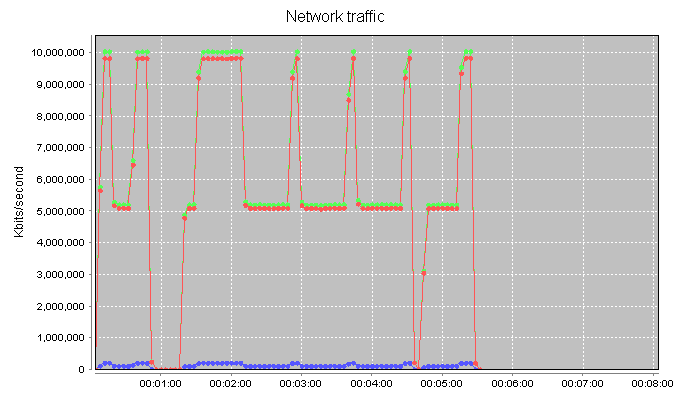
It took me a while to figure out that it was the Spirent blowing up here — and not the load balancer :-).
The nice graphs from the Spirent has also helped explain a lot of the problems I've been having in my test lab — which seems to be full of broken switches, dodgy network cards and iffy optics...
Do all test labs end up as a dumping ground for broken kit?

How to add Cloudflare in front of HAProxy



Related posts
ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Hardening HashiCorp Vault with load balancing for always-on security

How to load balance a MariaDB Galera Cluster for performance and HA using LVS & Ldirectord
A simple Citrix SSO replacement; with Okta, Apache and OpenID Connect

HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB
Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!