










15 reasons why you don't need a load balancer: Yes, really
If you want to test your site against this kind of attack, slow attacks like this are quite inexpensive for attackers to launch, and they don't need control of many remote hosts in order to launch an effective attack.

OK, time for another embarrassing confession, "For the last 15 years Loadbalancer.org has never needed to use a load balancer!" But that all changed when some hacker decided to attack our website.....
How can you trust a company that doesn't even use its own product?
Well first let's look at why we didn't use a load balancer for those 15 years...
Loadbalancer.org have 5 important information systems, listed here in order of importance:
- Support
- Web
- Phones
- CRM
Obviously we review the security and availability of these systems regularly, but we are fairly relaxed about a small amount of downtime for updates etc.
The last major outage was 7 years ago, and at that time we decided to move from our existing ISP to Amazon AWS.
Disaster recovery & security have always been our top priorities for company systems - not necessarily high-availability.
Because of this focus, our information systems are all cloud based, well documented and easy to recover.
Why we chose NOT to use a load balancer:
- Hassle
- Cost
- Complexity
- Maintenance
- Increased downtime
Read more here on why we didn't need 99.999% availability.
So how can you trust a company that gets taken down by a relatively simple DDOS attack?
Before answering that, let's look at what actually happened, and specifically what we did wrong.
The first mistake - not paying attention
Over a period of a few weeks, we'd noticed a couple of strange performance issues with the website, nothing too worrying, it just went on the list of things to look into at some point.
In hindsight, we also should have noticed it was at weird times, such as the weekend when traffic should have been low. We were doing a lot of updates around the same time and we even had a small outage at one point that we blamed on a glitch and re-booted :-).
We also don't do much logging or analysis of traffic, and although 70% traffic to our website comes through Sucuri (a cloud-based WAF), for historical & experimentation reasons we still have quite a large amount of direct traffic...so we can't blame them :-).
It just so happens that these spikes in traffic were quite likely a hacker (or automated tool) probing our defences with valid HTTP requests, and measuring the response time of each request...
The second mistake - The initial mis-diagnosis
Timing is everything, we have a standing joke in the office about doing updates on a Friday... "Web Site Down Friday" we call it. One of our newer members of staff had only done a website code update once before and was nervous about doing it themselves. Using our policy that the best way of learning is by breaking things we said go for it...everything was fine for about 30 minutes and then predictably the website went down! No problem we thought let's see how the new girl handles a bit of pressure to diagnose the fault and fix it...
What we didn't realise was that this was the start of an irregular wave of Slow HTTP DDOS attacks!
The third mistake - Confusion and more mis-diagnosis
To give her credit Emma was pretty calm, she double checked the script, re-ran it on a test environment, and diagnosed the live database as corrupt or broken. So she restored the live database from a backup and rolled back the changes anyway for good measure. So now we had a working test system with the new updates and a live server back how it was, everything worked for 10 minutes then went down again...
The fourth mistake - Too many cooks
By this time, a bunch of our geeks in the office were getting interested, they started circling like a bunch of vultures eager for the kill.
One started diagnosing the live traffic - and quickly found large numbers of suspicious requests - then started implementing iptables rate limiting on the live feed. One started moving the Amazon RDS database to a larger instance because they saw it was getting hammered. Another saw the dreaded OOM killer and increased the instance size and memory and started looking at the Apache config and one was puzzled that we were losing console access...
You can see the problem here, can't you?
We were two hours in and getting nowhere - we knew we were under some kind of small attack...
But the important point is that we were not stressed, and this was actually good fun!
The fifth mistake - Blaming Amazon
Now the fact that we were sometimes losing console access was really confusing, even when we fire-walled all external traffic we would sometimes lose access to both the web server and the database completely! We had this theory that Amazon was rate limiting us because it thought we were causing the attack - look it made sense at the time honest :-).
So we proceeded to move the whole site to Germany and change the DNS again (Isn't Amazon awesome?)
A final twist was when we then made a 'typo' in a database configuration in yet another test system and convinced ourselves we'd found the code problem... (just plain stupid).
Another 2 hours passed and we finally got around to putting a load balancer in front of the website and going live...
And everything was working again!
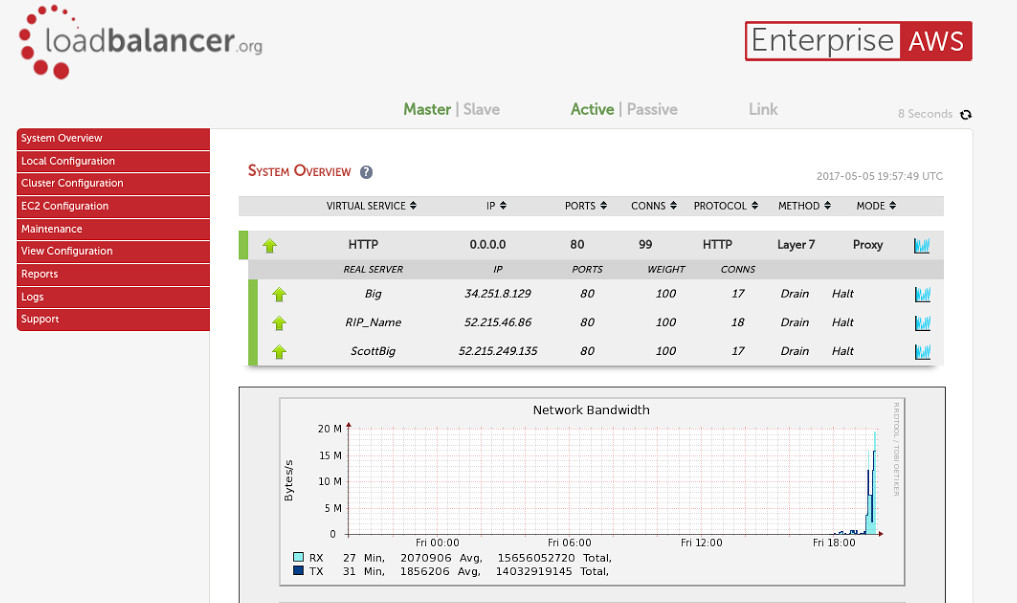
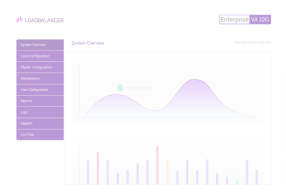
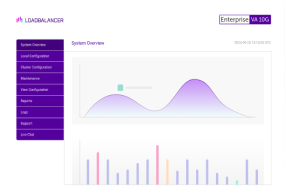
So why did the load balancer stop the attack?
Well take a look at the front end connections, 99 and yet the three backends only have 52?
This screenshot was actually taken as the attack was fading away and we could have hardened the Apache server against this kind of attack, but its far quicker and easier on a load balancer:
timeout http-request 5s
Well OK not quite, but at the time and just to be sure we went from:
One small web server & one small database -> 1 load balancer + 3 large web servers + 2 medium database servers.
Once the attack died off we went back to:
1 load balancer + 1 medium web server + 1 medium database.
If the attacker had been more persistent we could have enabled the WAF and tried to filter the specific URLs that the attacker was concentrating on...
The nice thing is that now we have a load balancer in front of the website we have much better visibility of what is happening in real time + historical graphs.
The post-diagnosis
If you want to test your site against this kind of attack Qualys have a great open source tool, slow attacks like this are quite inexpensive for attackers to launch, they don't need control of many remote hosts in order to launch an effective attack.
Current theory is that it was a small but clever DDOS attack at layer 7 of up to 225,000,000 Bytes/s (our normal highest load is 20,000,000)... so low and slow, yet as Ronen Kenig from Radware says "difficult to detect and not that easy to stop". The annoying thing is that they open the data channel with a real HTTP request & started listening but never closed it.. so memory on the
server was used up quickly... enough to cause a denial of service.....
Conclusion
OK, we definitely should have been better prepared and we should have hardened our Apache configuration, but:
- It was definitely a good learning process.
- Our disaster recovery definitely got tested.
- It gives us perspective on the kind of problems our customers need help with.
- We added a new feature to the product - Slowloris DOS protection will now be a default option and tick box feature of the web interface - rather than the current manual configuration.
- It shows these attacks are still fairly rare...
Let's open a discussion
Have you had a similar type of DDOS attack and how did you handle it?
Are you worried about these kinds of attacks getting stronger or more frequent?
Please let us know or just say how stupid we were in the comments section below.
Thank you.
More on DDoS
Should a load balancer be your 1st line of defense?

Leading European research university maintains top-class website with Loadbalancer.org



Related posts
HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Microsoft NLB is finally going End of Life — so what next?!
Load balancer migration: The F5 alternative turning heads
Loadbalancer.org announces leadership transition and next phase of growth
Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB

Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!
