











When it comes to data storage, we're often obsessed with chasing higher and higher throughput speeds to handle massive workloads (think AI and high-performance computing) — trying to transfer as much data as possible in the shortest amount of time.
But what if I told you the small stuff can sometimes cause an even bigger headache? Yep, I know, it seems counterintuitive, but small workloads can sometimes create a unique set of problems that are harder to solve. This is especially true for workloads with a large number of very small data packets or a high rate of small HTTP requests.
Here I'll break down why small objects can be troublesome, and explain how to route your S3 traffic by traffic size for more efficient data storage and management.
The problem: Bigger isn't always better when it comes to objects
The 'small objects problem'
When it comes to data storage, small objects can create BIG problems. It's not that there's something inherently wrong with little objects — they're just trickier to deal with. I'm going to call this the 'small objects problem'.
This can cause a number of issues. Specifically:
- Network congestion: High network traffic made of many small packets can overwhelm a network, especially since each packet needs to be processed individually, which adds a lot of overhead.
- High overheads: Using small packets is inefficient because the header information required for routing and delivery (like addresses and protocols) can take up more space than the actual data you're sending, which wastes a lot of bandwidth.
In contrast, large objects are simpler to handle because once the connection is established, the entire file can be transferred in one go. The systems then work together to sort out a window size and send as much data as possible. Compared to the file transfer the connection setup for large objects is a very small portion of all the data that is sent.
But with small objects the connection setup becomes a large part (or even the largest part) of the entire request. This means small objects are actually harder to deal with than larger objects.
So if your workload requires a lot of concurrent access to small objects as well as access to large objects, you are going to want to optimize where you store and access the items from. To do that, you need to make fast friends with IOPs...
Operations Per Second (IOPs)
Input/Output Operations Per Second (IOP) is a crucial performance metric used to measure how quickly a storage device, like a hard disk drive (HDD) or solid-state drive (SSD), can read and write data.
IOPs, or Input/Output Operations Per Second, is a key metric that measures a storage device's performance by counting the total number of individual read or write requests it can process in one second. Unlike throughput, which measures the volume of data transferred (e.g., megabytes per second), IOPs focuses on the frequency of these data access requests. This makes it a crucial indicator for workloads that involve a high number of small, random operations, such as those found in databases or virtualized environments, where the speed of processing each individual request is more important than the total amount of data being moved.
The table below nicely illustrates the vast differences in speed for Hard Disk Drives (HDD), Solid-State Drives (SSD), and Non-Volatile Memory Express (NVMe) SSDs, based on their Input/Output Operations Per Second (IOPS):
| Drive Type | Random IOPs | Sequential IOPs | Notes |
|---|---|---|---|
| HDD | 100-200 IOPS | 150-250 IOPS | Bulk and large file storage where speed is not a primary concern. |
| SSD | 70K-100K IOPS | 128K-140K IOPS | A mix of performance and capacity. |
| NVMe SSD | 400K-1M+ IOPS | 768K-1.79M IOPS | High performace for low latency and high throughput but with a higher cost per gigabyte |
Make sense?
What's the difference between IOPS and GBs?
It's easy to confuse IOPs with throughput, but they measure different things.
While IOPs measure the number of items moved per second (IOP) throughput measures the amount of data transferred (GB).
So if you're dealing with lots of small, random requests for small objects you'll be much more interested in IOP. Conversely, if you're streaming or transferring large files in sequence, you'll be more interested in throughput.
It's not an either-or, they're simply different problems to solve. Hence you can have a storage device with high IOPS but low throughput, or a storage device with low IOPs but high throughput. So both metrics are important, but the one we're focused on here is IOP.
With me so far? Excellent! So let's assume you have a high number of small files that are overwhelming your system's ability to process individual I/O operations. How do you fix it? Here's how...
Solution: Implement a content-length header
Implementing a Content-Length header rule can help overcome the small object problem by allowing your system to inspect the size of a file before it's fully received. This allows it to make smarter routing and storage decisions i.e. send small objects (>1-2MB) to NVMe nodes and large objects (<2MB) to HDD nodes.
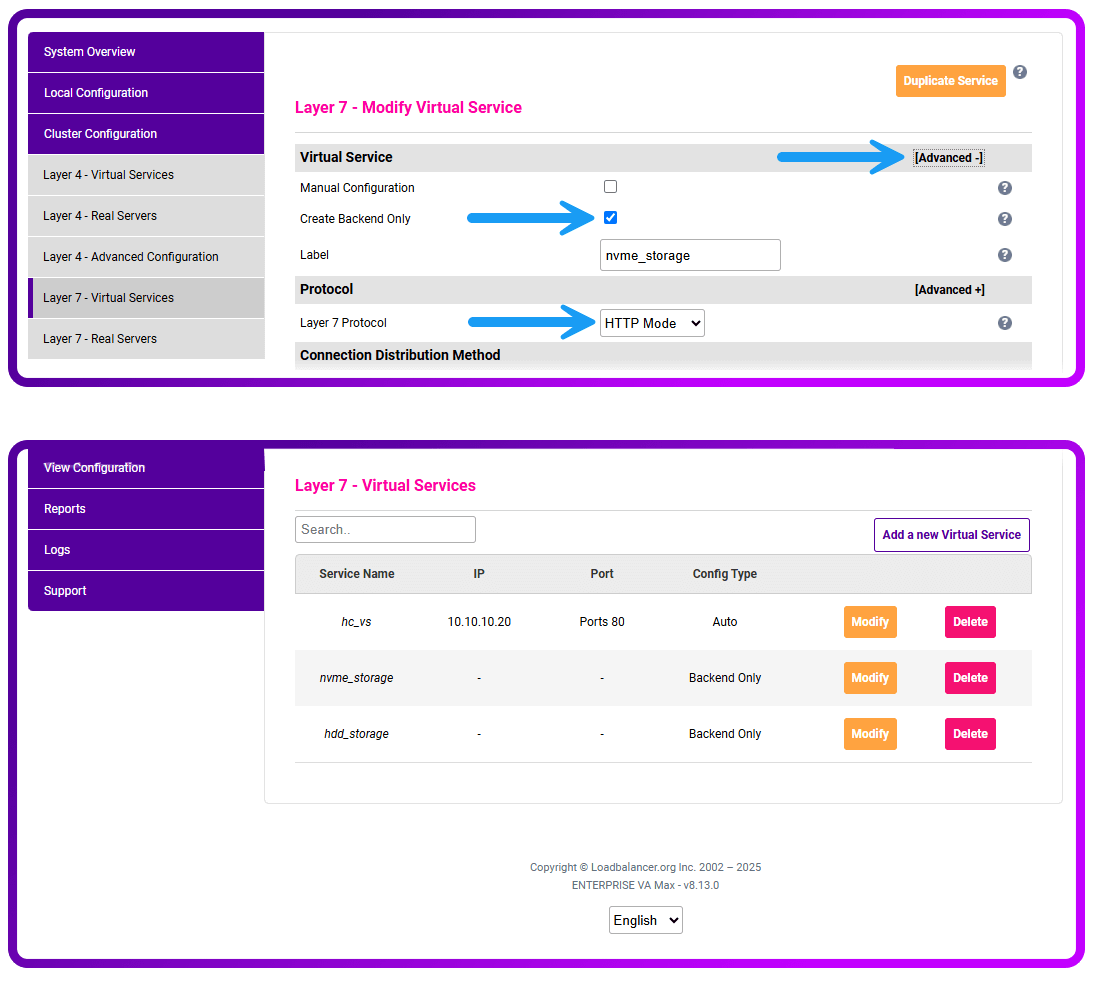
The Content-Length rule requires the Virtual Service to be moved away from Layer 7 TCP mode and instead be set as Layer 7 HTTP mode.
How to set up a content-length header on a Loadbalancer.org appliance
Follow the steps outlined in this Deployment Guide, then make the following adjustments/changes:
- Go to the S3 Virtual Service
- Change the "Layer 7 Protocol" to be "HTTP Mode"
- Add these ACL Rules to your S3 service:

4. Create backend only Virtual Service(s). You could just add one and then only use it if both ACL rules (http_put && large_object) match. Or, you can create it in the way that I did in this example. You will then need to add Real Servers to the backend(s).


And that's it!
Sometimes simple changes can make a BIG difference to performance!
Following the steps above should help you overcome the 'small objects problem'; allowing you to more effectively manage small objects by analyzing the PUT operations and payload size of your S3 traffic, determining the optimal nodes for data placement.
This will allow you to more effectively manage and optimize your data storage.
And for those times when you just need raw power, you can always use smart load balancing for 100x faster throughput!