










How to design a disaster recovery plan for your cloud infrastructure
To design a well-targeted disaster recovery plan, you need to work out two key metrics: the Recovery Point Objective (RPO) and the Recovery Time Objective (RTO).


Disaster recovery is a set of procedures and standards that enterprises follow to quickly recover from the effects of certain negative events. A severe bug that gets shipped with the latest code push, a cyber attack, or - in rare cases - a natural disaster qualify as a potential disaster that could cause service interruption. Since these events can lead the critical mission control functions to go down, a disaster recovery is essential to get your business back up, and resume critical functions with minimum downtime.
In this guest post, we’re going to explore our options to design a disaster recovery plan and how to effectively implement that plan in the cloud.
Designing a disaster recovery plan
A disaster recovery plan needs to be robust, effective and well-tested. Here are some of the considerations that will help you design a working procedure for quick disaster recovery.
Understand the key metrics
To design a well-targeted disaster recovery plan, you need to work out two key metrics. They are Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
RTO represents the maximum length of time that the data can be lost without having significant impact on the business. RPO on the other hand is the measure of how long your application can go offline.
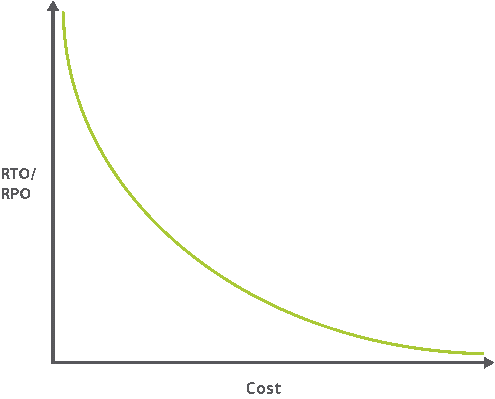
As pointed out in the graph, for smaller values of RTO and RPO, the cost will be significantly higher. However, these measurements assist system administrators narrow down on the optimal strategy for disaster recovery and help them select the most viable technologies.
Set your recovery goals
Create recovery goals that address your specific use cases. For instance, analysis and log data can have a higher value for RTO and RTO because speedy recovery of data is not important. However, you’d need the database and the server to maintain high levels of up time because if you don’t, you’d be losing customers. So you need to have a strategy to fail over the application to another location and create snapshots of the database and archive it regularly.
Integrate security mechanisms into the mix
The security measures that have been deployed into your production stack needs to be applied to the recovery mechanism. For instance, if you’re backing up your database or archiving it, ensure that the same rules that govern your hot database also apply to the backups.
Disaster recovery techniques - hot, warm and cold
Traditional disaster recovery techniques focused on speedy recovery of data since it directly relates to business continuity. Three different disaster recovery methods are popular in disaster recovery parlance: cold, warm and hot sites.
Hot sites helps your company recover in a matter of minutes. In the best scenario the hot site can be always-on, increasing both capacity and resilency. All the components including the application and the database are hosted on remote dedicated servers and real-time data replication is used to push the production to the hot site. This can be very expensive because you need to pay for more than one dedicated site and create an infrastructure to replicate the data for both the sites in real time.
A warm site on the other hand uses incremental backups and uses these to recover to the latest stable production environment. Depending on the amount of investment involved the warm site may take a long time to bring online — and in some cases; to reduce costs — the compromise of some data loss may be acceptable.
However, if your company is using the cloud to host your business, you have many flexible options. Public cloud services usually have disaster recovery plans integrated into them. Amazon, Azure, and IBM Cloud are great examples of top vendors offering disaster recovery services integrated into the cloud. For enterprises running on private cloud, you have alternatives that are more viable than the hot site approach.
Furthermore, solutions such as N2WS offer specific disaster recovery capabilities on top of those provided by the cloud vendors for enhanced protection, such as near-instant recovery time using incremental snapshots.
Disaster recovery using load balancers
Cloud providers and private cloud owners are moving towards load balanced data centers for disaster recovery. Load balancers can easily fit into a disaster recovery plan because chances are, your application has a load balancer already set up. Enterprises running on private cloud can use a load balancer to switch the users to another data center when disaster strikes. This way, the application will maintain high levels of uptime although the live data centers will be handling more traffic than what they are optimized for.
Disaster recovery using a load balancer satisfies both the metrics since it offers high values of RTO and RPO. Since the load balanced servers are always available, your business will have a high uptime. Additionally, security is not much of a concern because that’s usually taken care of already.
Many cloud service providers offer DNS based load balancing that can be used to fail over to a different site when a data center (availability zone) goes down. These DNS based load balancers are highly redundent, fast and reliable. They can even re-direct traffic traffic to a data center based on certain pre-defined rules. When a disaster happens, you can route the traffic to the live data center simply and quickly.
Good examples of DNS/Cloud based load balancers are Amazon Route 53 and CloudFlare. They are top level multi-cast DNS servers with monitoring, alerting and locality based routing built in. They are incredibly reliable and powerful.
However, you would usually implement these in combination with your local application delivery controllers on each site.
Why do you often need two load balancing layers?
The cloud based load balancers are mainly for routing external traffic, for high-availability between sites and possibly locality based routing. However, they are usualy only configured with a few basic health checks for your main external applications. So they can tell if your main web site is offline, or a data center is not responding - but they usually have no idea if potentially hundreds of internal applications are having availability problems.
So how does a traditional load balancer help with disaster recovery?
The main purpose of a local load balancer (application delivery controller) is to ensure that your application clusters on one local site have high-availability. They do this by balancing application requests across multiple servers, and removing servers from the cluster when they fail health checks. Obviously for redundancy you need two load balancers as well!
Scenario 1: Cloud load balancer + local load balancer
Let's say you have a small disaster — for example a single rack of servers has a power surge and you lose access to your Exchange cluster. Now assuming that your load balancer is in a different rack it will quickly realise that the application has had a total failure and bring up the fallback server (the default fall back server just says 'Sorry this application is down - try again later').
However, if you configure the fallback server to point to your Exchange cluster on on a remote site then you will get zero downtime! Admittedly it will probably be a lot slower on a high latency WAN link, but it would work.
Because of the latency issue the internal load balancer would also need to inform the cloud load balancer of the failure so that all external clients would go direct to the working site with low latency.
This kind of fallback option is often used on multi-site Exchange deployments, as it has the advantage that it still works for internal clients or external clients don't recognise that the cloud based DNS has changed.
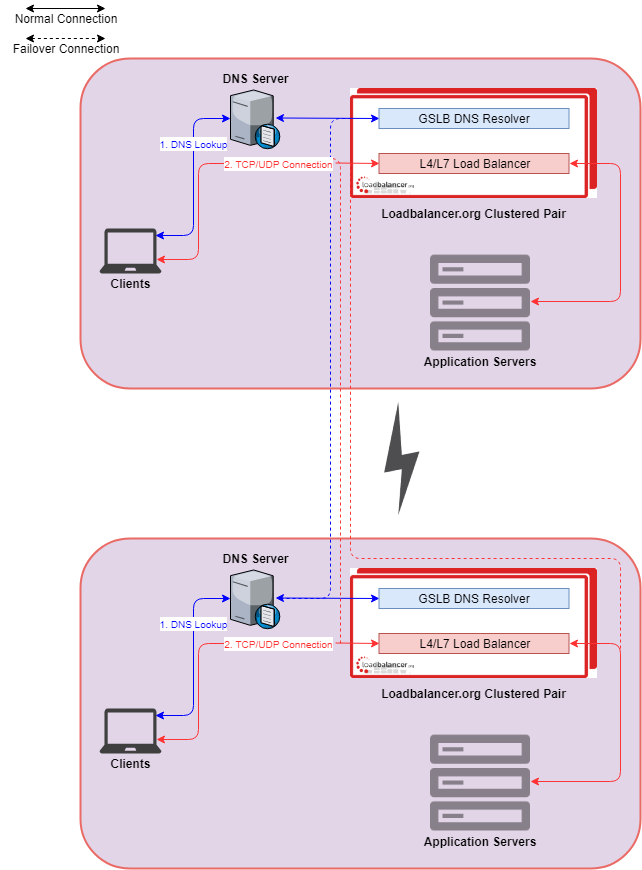
Scenario 2: Local GSLB + local load balancer
Sticking with the same example of a multi-site active active Exchange implementation.
What happens if the load balancer was in the rack that blew up?
In order to resolve this you can run a local GSLB (Global Server Load Balancer) aka. DNS server with health checks. A typical configuration would have two load balancers on each site and all 4 load balancers would be running a GSLB.
You would configure the local GSLB so that local clients would always use the local Exchange cluster using TWRR (Topology-based Weighted Round Robin).
If a single site fails then the local DNS server would query ALL of the GSLB servers until it got a valid response (which would give the address of the remote site). The local DNS server would then direct clients to the remote site.
But, there’s often a catch!
Designing a disaster recovery plan using any method, comes with certain strings attached. How do you recognize that one server is down and redirect all the traffic to the one online? The application’s configuration metadata, for instance, needs to be kept in sync between the data centers and that’s somewhat challenging without a centralized system in place. The configuration details include server names, IP addresses, DNS mappings, firewall rules, load balancer rules, details about clusters and containers that have been deployed, among other things.
Development, test and production have separate metadata and the process is usually automated and generated by a script. Since the generation of metadata is not integrated into the actual application, there’s the lack of a centralized infrastructure that handles all this. So you’d need a centralized tool to clone the configuration metadata in a data center sync it with the other data center it is load balanced with.
Finally, you’d need to test the load balancer by mocking a disaster event to ensure that the setup is foolproof against human errors and configuration errors. Untested configuration can result in more damage and continued losses in terms of downtime. Configuration metadata should be backed up in a centralized container so that if the latest configuration can be easily recovered if error occurs.
Summary
While planning for an unforeseeable disaster can be a difficult task, having sufficient funds allocated to implement an efficient IT disaster recovery plan can, at times, seem almost impossible. Since you can never predict whether a disaster could strike you or not, it’s a good idea to have a viable recovery plan that works for you.
Share your thoughts in the comments section below.

Does the new multi-threaded support in HAProxy finally solve the 10G problem?


Load balancing your load balancers for a crazy amount of SSL TPS

Related posts
Multi-AZ resilience: Why the recent AWS outage shows you need it

How Loadbalancer.org provided this medical imaging vendor with more technical and commercial flexibility in AWS

Why is public cloud potentially a bad idea from a programmer's perspective?

Cloudian takes object storage performance to the next level —with a tailored load balancer
HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB