











You've followed the Omnissa Horizon deployment guide (formerly VMware Horizon). The VIP is up. Health checks are green. Certificates look right. And users can log in without issue.
Then someone clicks Launch on their desktop, and the session never starts. Or only some users can connect. Or everything works from a clean test path, but starts to feel inconsistent once real users arrive from home networks, hotels, VPNs, mobile connections, or shared office egress.
That is the part of Omnissa Horizon that is easy to underestimate. It is not just a login page behind a load balancer. It is a session.
Once the user authenticates, the Secondary Horizon Protocols (Phase 2) still need to reach the same Unified Access Gateway (UAG) that handled the Primary Horizon Protocol (Phase 1). If that does not happen, the deployment can look healthy while the user experience breaks.
This article is about avoiding that gap. We will look at how Horizon’s primary and secondary protocols behave, why the external UAG tier is where most of the design decisions live, and how to choose the right load balancer pattern for your environment.
Table of contents
- Why Horizon behaves differently behind a load balancer
- Where the load balancer sits in a Horizon deployment
- What actually determines the right external UAG design
- Which Horizon pattern works best for your setup
- What actually matters on the Connection Server side
- Troubleshooting: Where people usually get caught out
- Final checks before you call the design ready
Why Horizon behaves differently behind a load balancer
When a Horizon Client connects, the first connection is the Primary Horizon Protocol (Phase 1) over HTTPS. After successful authentication, one or more Secondary Horizon Protocols (Phase 2) follow. Depending on the environment, those can include HTTPS Tunnel, Blast, and PCoIP.
For external clients, those secondary protocols still need to reach the same Unified Access Gateway (UAG) that handled the primary protocol. If they do not, the session can fail even though authentication succeeded. That is why “login works but launch fails” is such a common Horizon symptom.
The split inside the platform matters too. On the inside, the Connection Server handles authentication, entitlement, and broker logic. On the outside, the UAG accepts the remote session and makes sure only authenticated traffic is allowed to continue. From a load balancer point of view, that is the real problem to solve. The design is not just about keeping a VIP online. It is about making sure the right parts of the Horizon session continue to land in the right place. Before choosing a persistence method or deployment mode, it helps to separate the two load-balancing jobs in a Horizon deployment: the internal Connection Server tier and the external UAG tier.
Where the load balancer sits in a Horizon deployment
A Horizon environment has two distinct load balancing layers, and they solve two different problems.
The first is the internal Connection Server tier. This is the broker layer. A VIP in front of the Connection Servers gives users, admins, and UAGs a single, stable address for authentication, entitlements, and desktop brokering. It removes any single Connection Server as a point of failure and lets the broker tier scale cleanly.
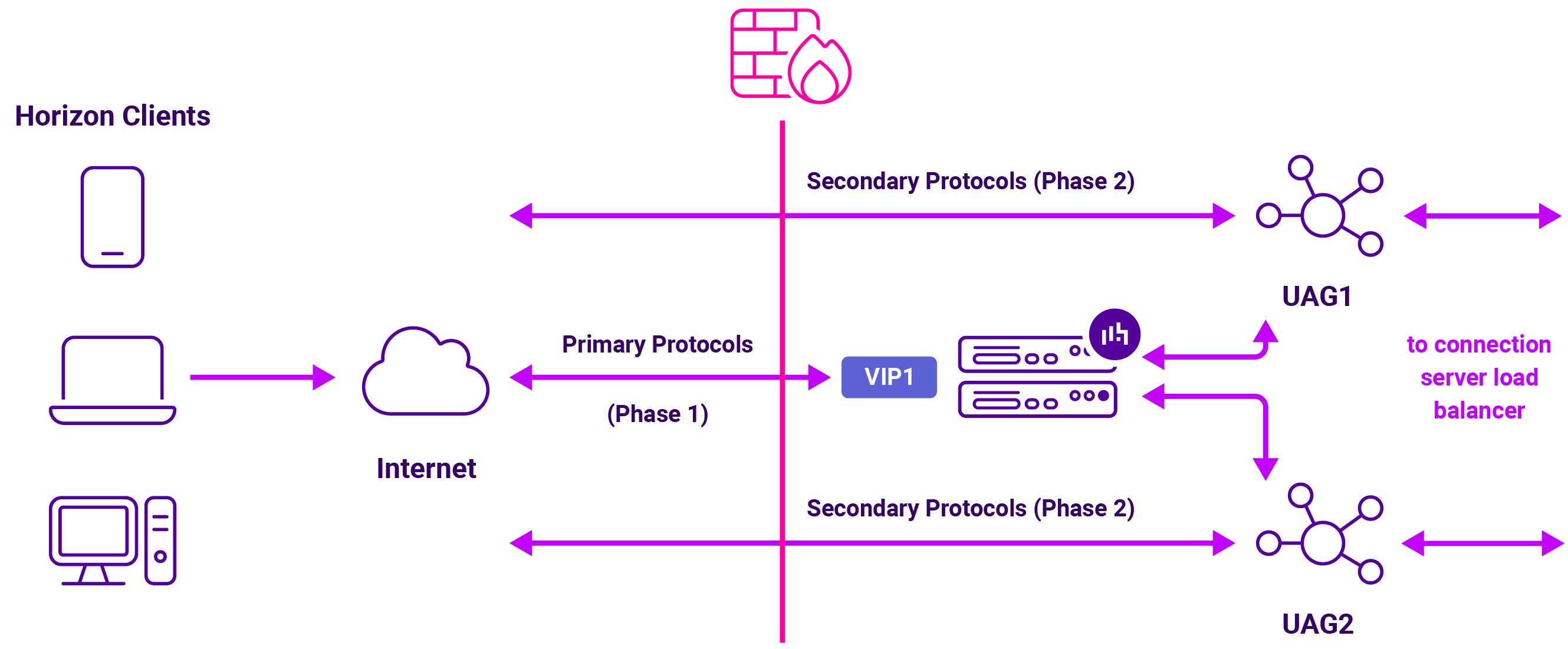
The second, and more sensitive, layer sits in front of the Unified Access Gateways. This is the external access tier. Here, the load balancer is not just distributing traffic. It also has to keep each Horizon session tied to the same UAG from the first connection through the secondary protocols.
That difference is important. The Connection Server VIP is mostly about clean presentation and high availability. The UAG VIP is about session continuity: persistence, public IP addressing, routing, default gateway, and return-path behaviour.
Mix those two problems together and the design quickly becomes harder to reason about and troubleshoot.
In a clean, from-scratch deployment, the best approach is usually one clustered load balancer pair for the external UAG tier and a separate clustered pair for the internal Connection Servers.
You will still see both roles handled by a single pair, especially in migrations or environments that grew organically. That can work, but it should be a deliberate choice, not the default.
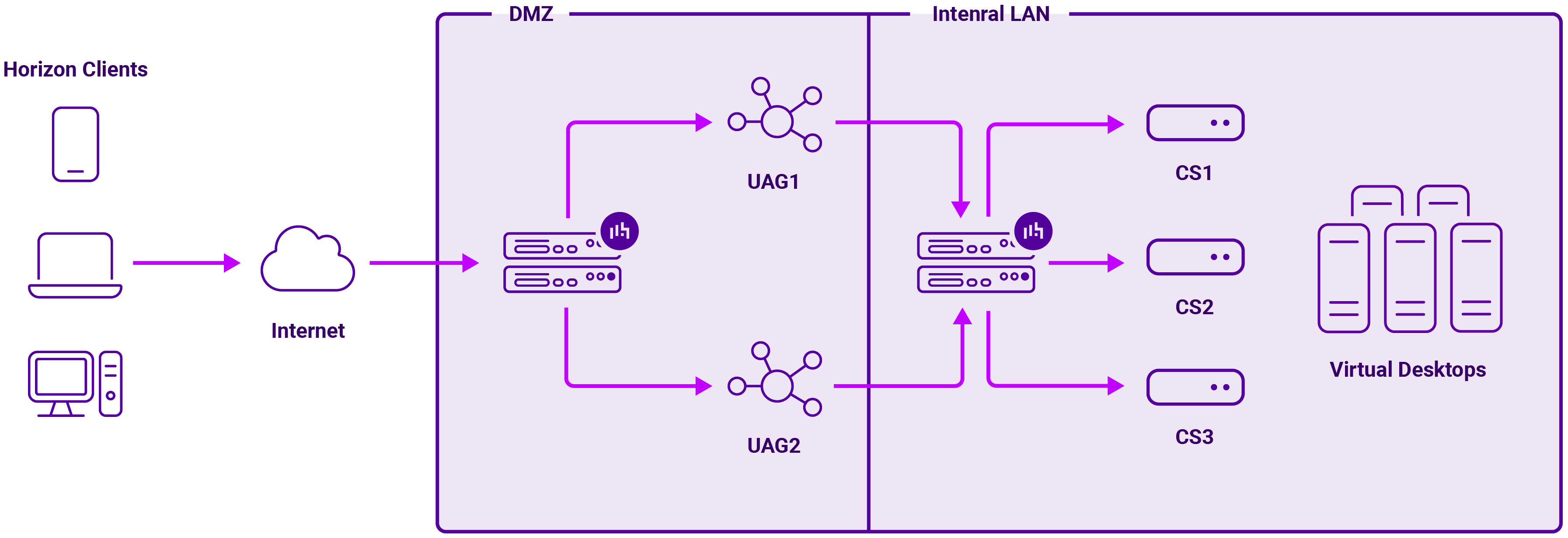
Image caption: Overall Horizon topology showing the external UAG load balancer tier and the internal Connection Server load balancer tier
What actually determines the right external UAG design
Once the Horizon terminology is out of the way, the right external design almost always comes down to three practical questions.
Is NAT in the path?
This decides whether source IP address persistence is even viable.
If the load balancer sees real, stable client IPs, source IP address persistence works cleanly.
But in many real-world deployments, the load balancer sees shared egress instead — home broadband NAT, mobile carriers, hotel Wi-Fi, corporate proxies, VPN concentrators, and similar paths. In those cases, the source IP no longer represents one user. It may represent dozens or hundreds of users behind the same public address.
That is usually the moment source IP address persistence stops being the clean answer, even if it looked perfect in a lab.
How much public reachability do you have?
This matters just as much.
If each UAG can have its own public-facing identity, you get more design freedom. The primary protocol can be load balanced, and the secondary protocols can go straight back to the correct UAG.
If you only have one public IP address to work with, the design becomes more constrained. You either keep more of the session behind the load balancer, or use a port-based approach like Option 3.
Do you want all external traffic through the load balancer, or only the primary protocol?
Some designs keep the load balancer in the path for the entire session, including the primary and secondary protocols. Others use the load balancer only for the initial login, then let the secondary protocols go directly from the client to the UAG that owns the session. Neither approach is universally better. They fit different constraints.
So before you pick one of the three external patterns, answer these questions first:
- Is NAT expected in the client path?
- Do you have one public IP address, or public reachability per UAG?
- Do you want all traffic through the load balancer, or only the primary protocol?
Which Horizon pattern works best for your setup?
The three options below map directly to the three questions we just covered. Each one is valid. The right choice depends on NAT, public reachability, and how much traffic you want to keep behind the load balancer.
External clients: Option 1
The load balancer uses a single VIP with source IP address persistence to handle the Primary Horizon Protocol (Phase 1). The UAG URLs are configured so the Secondary Horizon Protocols (Phase 2) are also sent back to that same VIP and persisted back to the same UAG.
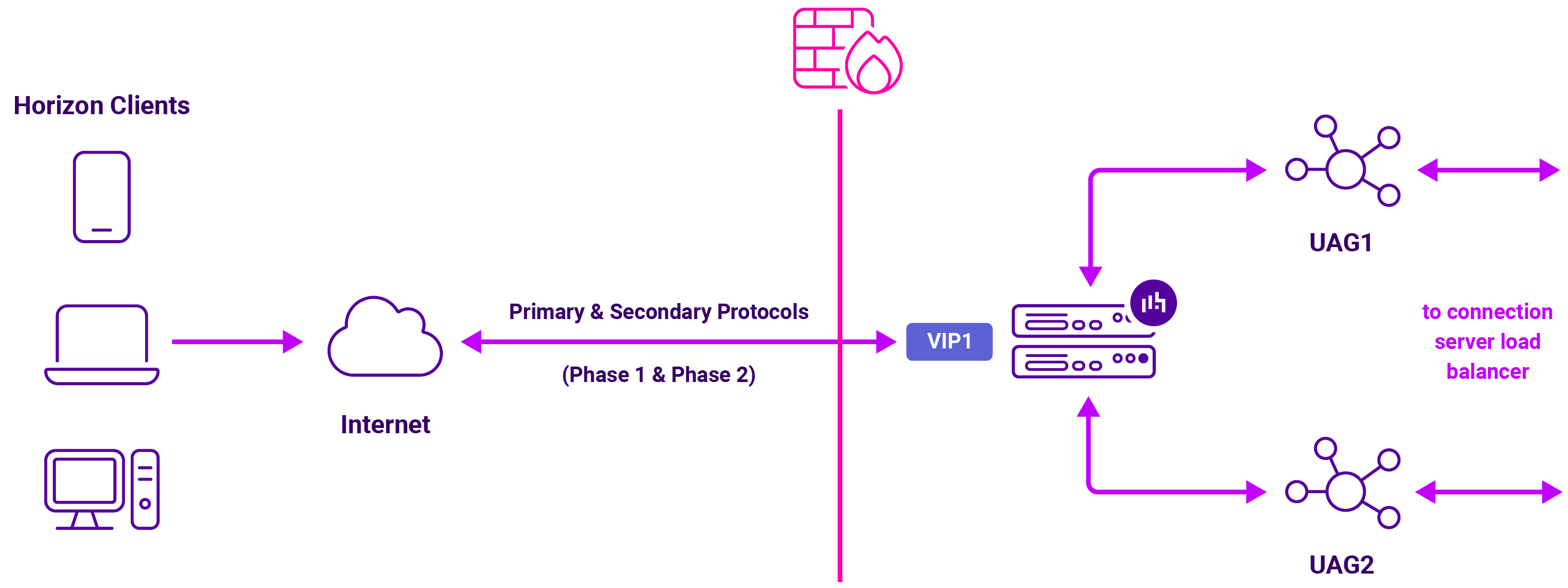
This option needs only one public IP address and keeps the entire session behind the load balancer.
On a Loadbalancer.org Enterprise appliance that means:
- Deployment mode: Layer 4 NAT mode
- Persistence: Source IP address persistence
- Public IPs needed: 1
- Default gateway of the UAGs: The load balancer, use a Floating IP in a clustered pair
- Ports: 443, 4172, and 8443, using TCP and UDP as required
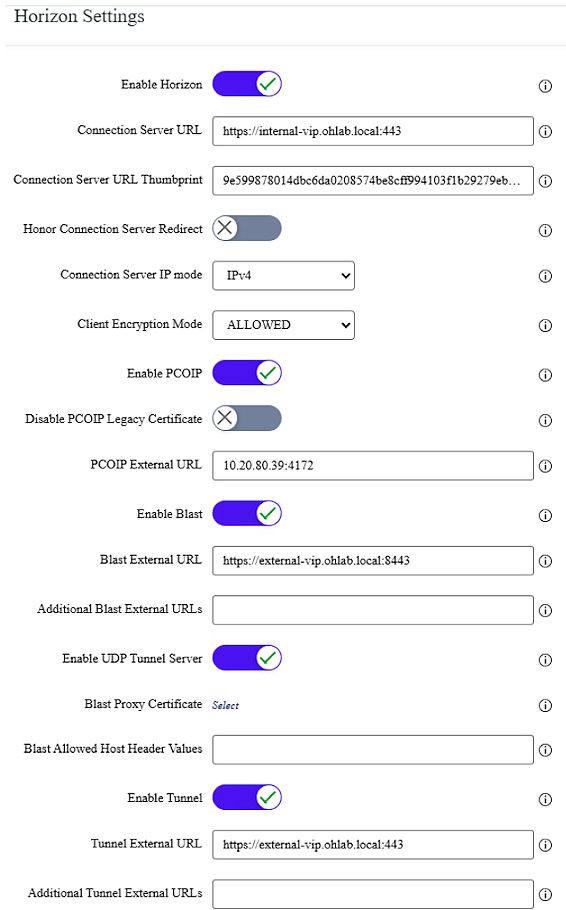
Option 1 UAG URLs, secondary protocols point back to the shared external VIP, so all traffic stays behind the load balancer:
External clients: Option 2
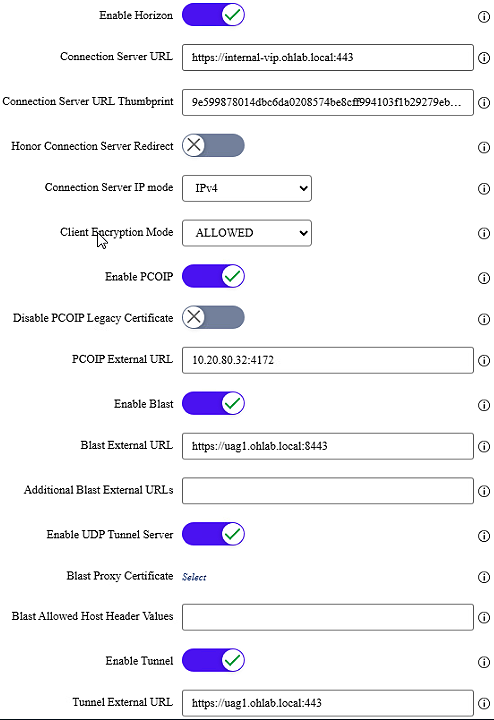
The load balancer handles only the Primary Horizon Protocol (Phase 1). Once the session is established, the Secondary Horizon Protocols (Phase 2) go directly from the client to the same UAG.
This option requires multiple public IPs: one for the VIP and one per UAG.
On a Loadbalancer.org appliance, that translates as:
- Primary VIP deployment mode: Layer 7 SNAT mode
- Persistence: Source IP address persistence in TCP mode, or cookie based persistence in HTTP mode
- Public IPs needed: VIP plus one per UAG
- Default gateway of the UAGs: The external firewall
If you use cookie-based persistence, the load balancer must see the UAG session cookie — so terminate SSL on the load balancer and re-encrypt to the UAGs with the same certificate.
The UAG URL fields are critical here:
- Connection Server URL: VIP of the internal Connection Servers -
- PCoIP External URL: Public IP address of the individual UAG
- Blast External URL: FQDN of the individual UAG
- Tunnel External URL: FQDN of the individual UAG
Option 2 UAG URLs, secondary protocols point directly to the individual UAG:
External clients: Option 3
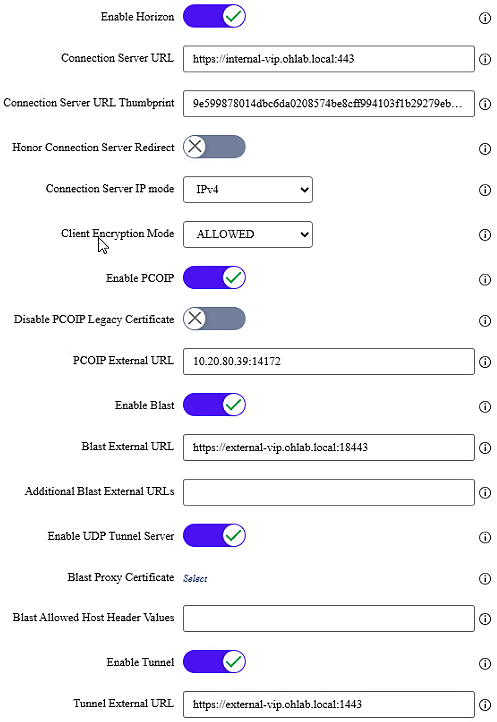
The load balancer uses one VIP for the Primary Horizon Protocol (Phase 1), then additional VIPs on unique external port numbers so the Secondary Horizon Protocols (Phase 2) still reach the correct UAG.
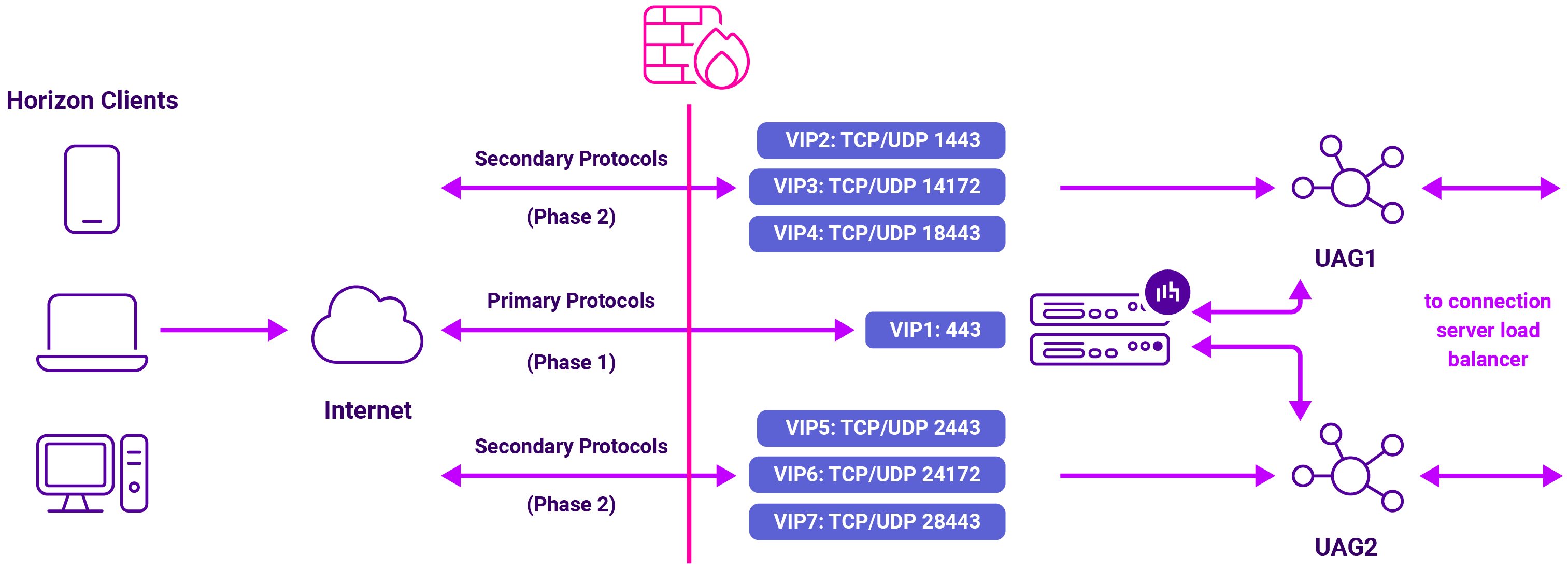
This keeps the deployment behind a single public IP address while still giving each UAG its own external port set.
Here's an example external port plan:
UAG1
- Tunnel / HTTPS: `external-vip.example.com:1443`
- Blast: `external-vip.example.com:18443`
- PCoIP: `<public-ip>:14172` -
UAG2
- Tunnel / HTTPS: `external-vip.example.com:2443`
- Blast: `external-vip.example.com:28443`
- PCoIP: `<public-ip>:24172`
On the UAG side, the services still use the standard ports: 443, 4172, and 8443. The external port plan tells the load balancer which UAG and service the traffic is intended for.
On a Loadbalancer.org appliance, that means:
- Primary VIP: Layer 7 SNAT mode
- Secondary VIPs: Layer 4 NAT mode
- Persistence on the primary VIP: Source IP address persistence or cookie based persistence
- Public IPs needed: 1
- Default gateway of the UAGs: The load balancer, use a Floating IP in a clustered pair
Option 3 UAG URLs, secondary protocol URLs use different external ports so traffic returns to the correct UAG:
Which option is usually the cleanest?
There is no universal winner. It depends on the constraints you are working with.
If source IP address persistence is genuinely safe and you want one clean public VIP with all traffic behind the load balancer, Option 1 is the natural starting point.
If you can give each UAG its own public reachability, Option 2 is often the cleanest design because it limits the load balancer to the primary protocol and lets the rest of the session go straight back to the correct UAG.
If you need to keep a single public IP but still want the load balancer involved in steering the secondary protocols, Option 3 fits that constraint.
A quick way to choose:
| Option | Best fit | Primary traffic | Secondary traffic | Persistence | Public IPs needed | UAG return path |
|---|---|---|---|---|---|---|
| 1 | One public IP + source IP persistence is safe | Via load balancer | Via load balancer | Source IP | 1 | Via load balancer Floating IP |
| 2 | Public reachability per UAG (NAT may exist) | Via load balancer | Direct to UAG | Source IP or cookie | VIP + one per UAG | External firewall |
| 3 | One public IP + secondary traffic still needs LB steering | Via load balancer | Via load balancer using unique ports | Source IP or cookie on primary VIP | 1 | Via load balancer Floating IP |
What actually matters on the Connection Server side?
Compared with the UAG tier, the Connection Server side is usually not where the external design becomes fragile.
Its job is still important. The internal VIP gives users, admins, and UAGs a single, stable address for the broker service. It removes any single Connection Server as a point of failure and lets the broker tier scale cleanly.
The most common mistake here is not the VIP itself. It is hostname presentation.
If the Connection Servers sit behind a load balancer, Horizon needs to hand back the VIP FQDN, not the name of an individual broker. That is why `locked.properties` matters. Set `balancedHost` to the VIP FQDN used for browser-based access.
In production, `allowUnexpectedHost=true` should be disabled and the expected FQDNs should be listed explicitly. It is useful in testing, but leaving it enabled in production weakens hostname validation and should be avoided.
Troubleshooting: Where people usually get caught out
Most Horizon load-balancer problems are not exotic. They usually come down to one of four things:
- The Primary Horizon Protocol (Phase 1) never completes
- The Secondary Horizon Protocols (Phase 2) do not stay on the same UAG
- The UAG URLs do not match the option that was actually built
- The return path does not match the deployment mode
If I were dropped into a live issue, I would start with the symptom I actually see.
If users cannot get in at all
Start with the Primary Horizon Protocol (Phase 1) path: client → VIP → UAG → Connection Server.
Ignore Blast and PCoIP for now.
Check:
- Can the client reach the VIP on port 443?
- Is the certificate correct?
- Can the UAG reach the internal Connection Server VIP?
- If SAML is in use, is the identity side healthy?
SAML issues can masquerade as load balancer problems. Some quick checks:
- The Connection Server must trust the real IdP, not the UAG
- The Connection Server SP metadata URL must be valid
- The UAG external hostname and issuer settings must match the VIP hostname clients actually use
- Clocks matter, so check time sync between the Connection Server, UAG, and IdP
If SAML worked yesterday but fails today, check time skew early.
If login works but launch fails
This is the classic Horizon symptom. Treat it as a Secondary Horizon Protocols (Phase 2) problem until proven otherwise.
The primary connection succeeded, but the secondary protocols did not make it back to the same UAG. Check:
- Does the persistence method match the real client path?
- Is source IP address persistence still valid once real users arrive behind NAT?
- Are cookie based persistence and SSL handling configured correctly?
- Do the UAG URL fields exactly match the option you built?
SAML can complicate this too. It adds redirects and POSTs early in the flow. If the browser does not send the UAG session cookie back after the IdP redirect, the request can land on the wrong UAG before the session is fully established.
If some users work and others do not
Suspect hidden NAT first.
Source IP address persistence can look fine in a lab, then become the wrong fit once multiple users share the same public egress.
If you need to prove whether persistence is really working
Temporary cookie logging on the VIP is one of the fastest ways to separate a persistence problem from an IdP or SAML issue.
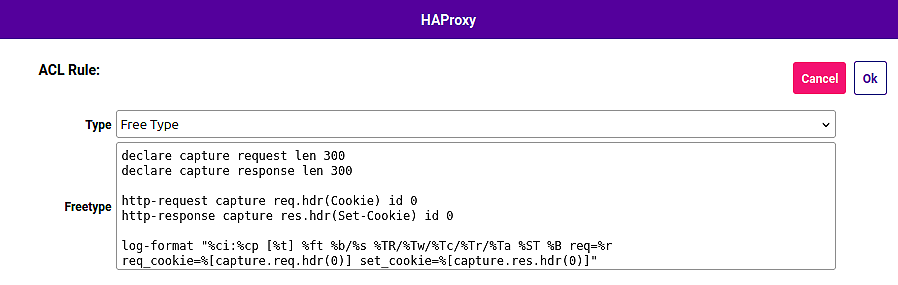
A practical HAProxy example looks like this:
```haproxy
declare capture request len 300
declare capture response len 300
http-request capture req.hdr(Cookie) id 0
http-response capture res.hdr(Set-Cookie) id 0
log-format "%ci:%cp [%t] %ft %b/%s %TR/%Tw/%Tc/%Tr/%Ta %ST %B req=%r req_cookie=%[capture.req.hdr(0)] set_cookie=%[capture.res.hdr(0)]"
```
Example log showing the `ACCESSPOINTSESSIONID` cookie:
```text
2026-01-06T10:27:22.14+00:00 external-lb haproxy[14479]: 10.20.80.2:65106 [06/Jan/2026:10:27:22.101] Option-2-UAG-external-vip-ohlab-local Option-2-UAG-external-vip-ohlab-local/uag2-ohlab-local 0/0/0/36/36 200 7199 req=GET /portal/?includeNativeClientLaunch=true HTTP/1.1 req_cookie=JSESSIONIDHTMLACCESS=0219029EDB9AD53F6332261DAA12E680; JSESSIONID=BB3A8D754D23BE3384A530706E07B490; SERVERID=uag2-ohlab-local; ACCESSPOINTSESSIONID=531fe13a-eee0-4372-a894-0cce69f443e1 set_cookie=ACCESSPOINTSESSIONID=531fe13a-eee0-4372-a894-0cce69f443e1; path=/; secure; HTTPOnly; SameSite=Lax
```HAProxy learns the `ACCESSPOINTSESSIONID` from the `Set-Cookie` header in the response and uses it to pin subsequent requests to the same UAG. If you see the cookie being set and sent back consistently, persistence is probably not your problem. If it is missing or inconsistent, that is where to focus.
If the design uses Layer 4 NAT mode
Check the return path early.
In Layer 4 NAT mode, return traffic must flow back through the load balancer.
It is not optional. This is especially important for Option 3. If the design depends on a per-UAG port plan, double-check that the UAG URLs, firewall rules, VIP ports, real server ports, and return routing all match exactly.
Final checks before you call the design ready
Before you put this anywhere near production, make sure you can answer these questions clearly:
- Which external option are we actually using?
- Does the persistence method match the real client path?
- Do the UAG URLs exactly match the chosen option?
- If Layer 4 NAT mode is involved, does return traffic pass back via the load balancer?
- If the Connection Servers are behind a VIP, is `balancedHost` set correctly in `locked.properties`?
- If cookie based persistence is used, is SSL offload and certificate handling correct?
And one final test: hit the environment the way real users will — from home networks, mobile connections, VPNs, and shared egress — not just from a clean lab path.
Closing thought
Horizon behind a load balancer is not difficult because the product is unusual. It becomes difficult when the deployment ignores how the primary and secondary protocols actually behave.
If you keep one thing in mind, keep this:
- The secondary protocols must stay tied to the same UAG as the primary protocol.
Once that is clear, the rest gets much easier to reason about. Choose the option that matches your constraints, build it with the same assumptions your deployment uses, and validate it with the same kind of traffic your users will actually bring.
Load balancing Omnissa Horizon?
Check out our step-by-step deployment guide
The Citrix NetScaler vulnerability crisis: When your load balancer becomes a liability


Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!

Related posts
Finally, a simple way to convert MaxMind GeoIP Database files to the legacy DAT format!
The Citrix NetScaler vulnerability crisis: When your load balancer becomes a liability
Hardening HashiCorp Vault with load balancing for always-on security
What's the best cloud load balancer? AWS, Azure, GCP, Cloudflare, or a third-party alternative?
HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB