










Load balancing Cribl Stream
Updated on February 3, 2026
•
Published on April 2, 2025
Benefits of load balancing Cribl Stream
The top three benefits of load balancing Cribl Stream, whether for inbound data to Worker Nodes or outbound data to destinations, are:
- High Availability (HA): By distributing the data processing load across multiple Worker Nodes, load balancing prevents any single point of failure from causing an outage. If a Worker Node or a downstream destination server fails, the load balancer automatically redirects traffic to the remaining healthy servers, ensuring continuous data flow and processing. This allows for seamless maintenance and upgrades without downtime.
- Scalability and optimized performance: Load balancing allows Cribl Stream to efficiently handle very large volumes of data by distributing the incoming and outgoing traffic evenly across multiple processing resources (Worker Nodes/Worker Processes). It ensures that no single server or process becomes overwhelmed, maximizing throughput and reducing latency. For inbound traffic, load balancing across worker processes can lead to 100% resource utilization and linear scaling of throughput.
- Efficient resource utilization: Load balancing ensures that all available resources (Worker Nodes and their individual Worker Processes) are utilized effectively, distributing the workload fairly based on factors like server capacity or historical load. Cribl Stream’s outbound load balancing algorithms use destination weights and historical data to ensure that data is distributed as fairly as possible to all available endpoints over time, preventing disproportionate loading of any one destination.
About Cribl Stream
Cribl Stream is a vendor-agnostic data pipelining engine for routing and processing IT and security data, allowing you to route, reduce, reformat, enrich, or shape data from any source to any destination.
The software allows you to instrument everywhere, gain more insights from analytics tools, and retain more data for longer periods of time, while paying less.
Why Loadbalancer.org for Cribl Stream?
Loadbalancer’s intuitive Enterprise Application Delivery Controller (ADC) is designed to save time and money with a clever, not complex, WebUI.
Easily configure, deploy, manage, and maintain our Enterprise load balancer, reducing complexity and the risk of human error. For a difference you can see in just minutes.
And with WAF and GSLB included straight out-of-the-box, there’s no hidden costs, so the prices you see on our website are fully transparent.
More on what’s possible with Loadbalancer.org.
How to load balance Cribl Stream
The load balancer can be deployed in four fundamental ways: Layer 4 DR mode, Layer 4 NAT mode, Layer 4 SNAT mode, and Layer 7 Reverse Proxy (Layer 7 SNAT mode).
For Cribl Stream, Layer 7 Reverse Proxy is recommended.
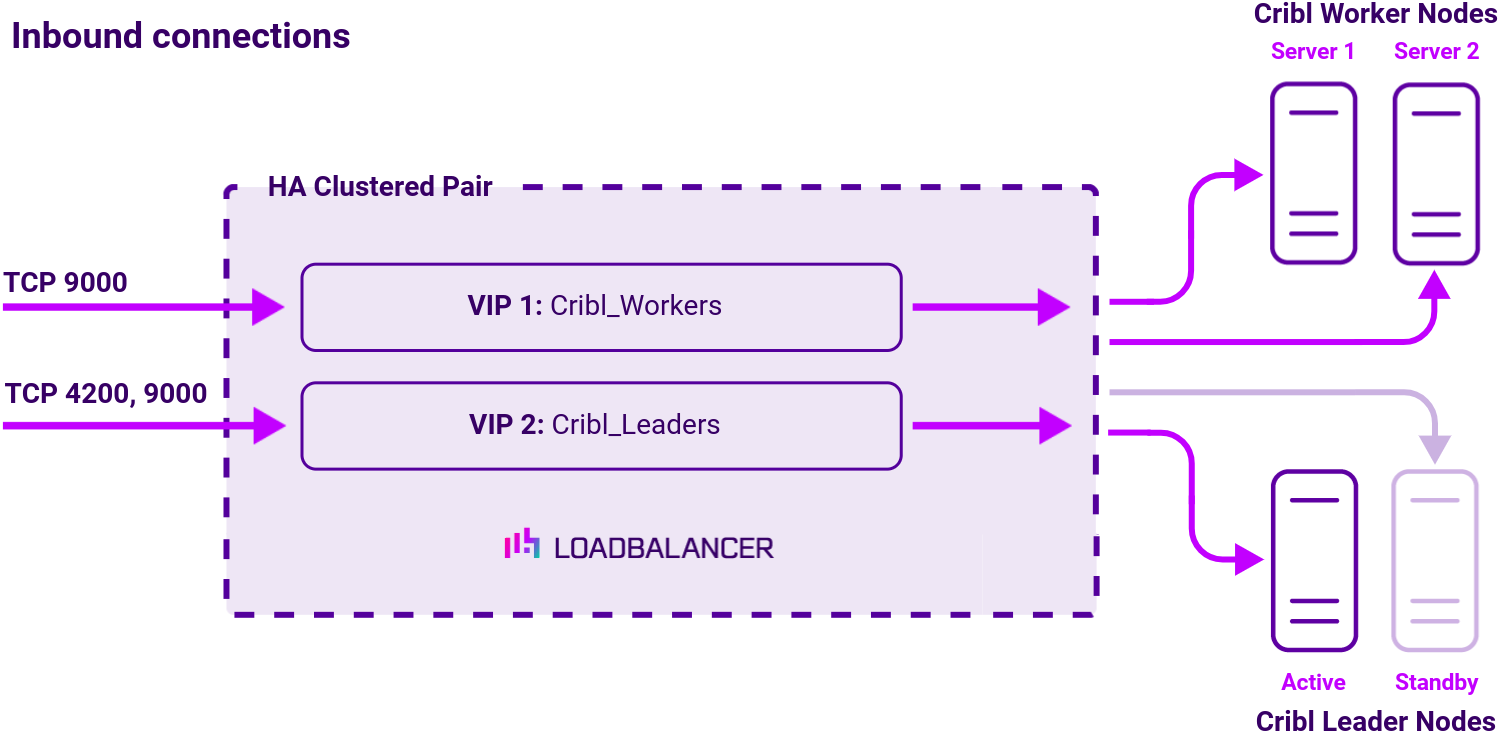
Virtual service (VIP) requirements
To provide load balancing and HA for Cribl Stream, the following VIPs are required:
| Ref. | VIP Name | Mode | Port(s) | Persistence Mode | Health Check |
|---|---|---|---|---|---|
| VIP 1 | Cribl_Workers | Layer 7 Reverse Proxy | 9000 | Source IP | HTTPS (GET) |
| VIP 2 | Cribl_Leaders | Layer 7 Reverse Proxy | 4200,9000 | Source IP | HTTPS (GET) |
Load balancing deployment concept
Once the load balancer is deployed, clients connect to the Virtual Services (VIPs) rather than connecting directly to one of the Cribl Stream servers. These connections are then load balanced across the Cribl Stream servers to distribute the load according to the load balancing algorithm selected:
About Layer 7 Reverse Proxy load balancing
Layer 7 Reverse Proxy uses a proxy (HAProxy) at the application layer. Inbound requests are terminated on the load balancer and HAProxy generates a new corresponding request to the chosen Real Server. As a result, Layer 7 is typically not as fast as the Layer 4 methods.
Layer 7 is typically chosen when enhanced options such as SSL termination, cookie based persistence, URL rewriting, header insertion/deletion etc. are required, or when the network topology prohibits the use of the Layer 4 methods.
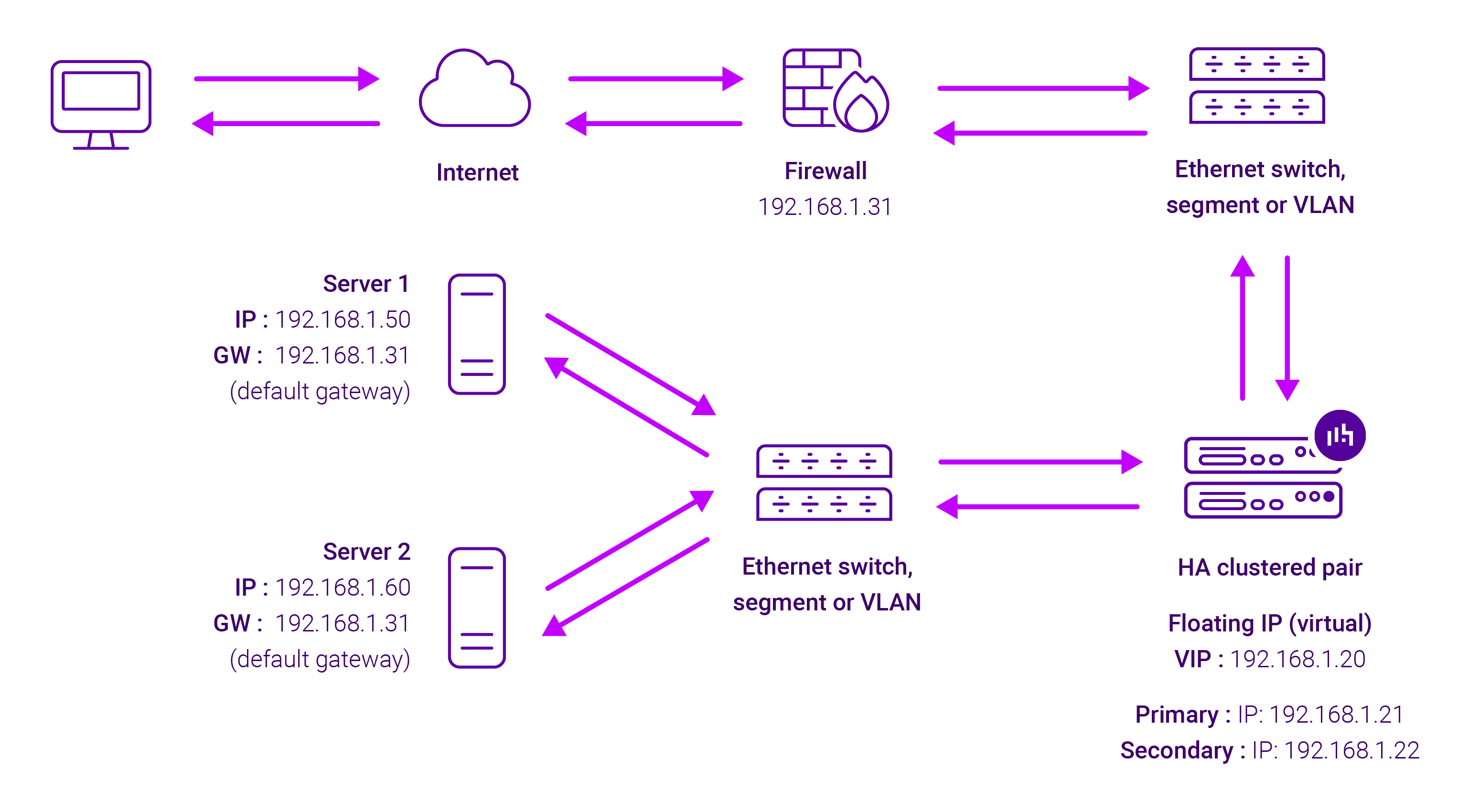
Because Layer 7 Reverse Proxy is a full proxy, any server in the cluster can be on any accessible subnet, including across the Internet or WAN.
Layer 7 Reverse Proxy is not transparent by default i.e. the Real Servers will not see the source IP address of the client, they will see the load balancer’s own IP address by default, or any other local appliance IP address if preferred (e.g. the VIP address). This can be configured per Layer 7 VIP.
If required, the load balancer can be configured to provide the actual client IP address to the Real Servers in two ways:
- Either by inserting a header that contains the client’s source IP address, or
- By modifying the Source Address field of the IP packets and replacing the IP address of the load balancer with the IP address of the client.
Layer 7 Reverse Proxy mode can be deployed using either a one-arm or two-arm configuration. For two-arm deployments, eth0 is normally used for the internal network and eth1 is used for the external network, although this is not mandatory.
No mode-specific configuration changes to the load balanced Real Servers are required.
Port translation is possible with Layer 7 Reverse Proxy e.g. VIP:80 → RIP:8080 is supported. You should not use the same RIP:PORT combination for Layer 7 Reverse Proxy VIPs and Layer 4 SNAT mode VIPs because the required firewall rules conflict.
