










The easiest way to reduce downtime — avoid a single point of failure
We get a lot of customers asking to buy a single load balancer. Understandably. One is cheaper than two. But here's why you might want a pair.

We get a lot of customers asking to buy a single load balancer. Understandably. One is cheaper than two. But here's why you might want a pair...
A load balancer plays a crucial part in avoiding catastrophic downtime to your application environments. Here I'll walk you through how you can maximize your uptime by avoiding what we call "a single point of failure."
A single point of failure
The first question is, what do you mean by a single point of failure? By this, I mean that if any component in your network goes down, this will result in downtime for the client. This could be because of a failure in a single connection with an application server. If the server goes down, no user will be able to access the application, which creates a huge vulnerability within any network.

You can easily avoid this, by using a single load balancer to scale out your back-end servers. In fact, this is exactly what a load balancer is built for — to scale out the application servers. This provides redundancy and protects against downtime by allowing you to have more users connect to your application, without causing a single server to crash due to too many connections.
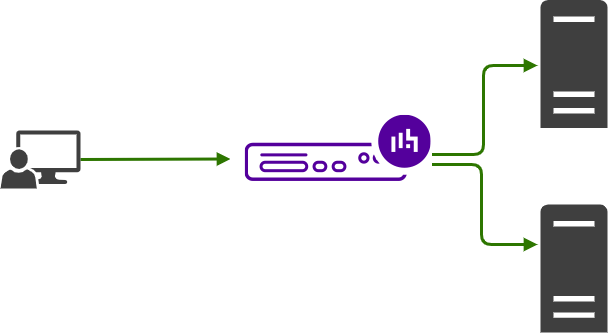
Although this solves your problem and you can scale out to hundreds of back-end servers, there is still a single point of failure in your network. You've simply changed the location.
Now your single point of failure is the load balancer appliance itself...
Moving up the single point of failure
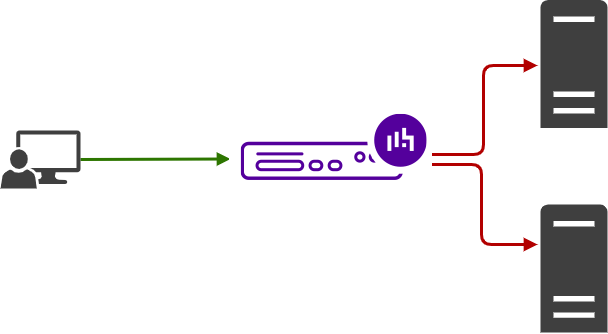
If your load balancer now loses its internet connection, power, or breaks for any reason, you will now lose connection to all of your backend servers. We call this moving up the single point of failure, as you have moved the single point of failure up from the application servers to the load balancer.
So how do you avoid the downtime this causes? We have a way around this.
The mirrored pair
By making our appliance highly available, we can now have a second, standby load balancer, ready to take over if the primary appliance fails for any reason, giving you an extra layer of redundancy and protection against downtime.
This is just as important on a virtual box as it is on hardware. We host our virtual appliance on a virtual hypervisor host. We recommend trying to keep virtual nodes on different hosts where possible. If you only have one host and this goes down, the host becomes your single point of failure. Having two virtual hosts, with a load balancer on each, again ensures redundancy through the whole network chain.
You can also mix and match hardware and virtual load balancers for high availability if you don't have two hosts.
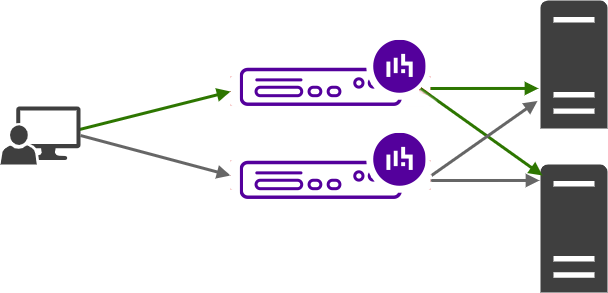
Should the secondary appliance notice that the primary appliance is down, a failover will occur, and the secondary appliance will take over, becoming active. This ensures that no new client connections experience any prolonged downtime.
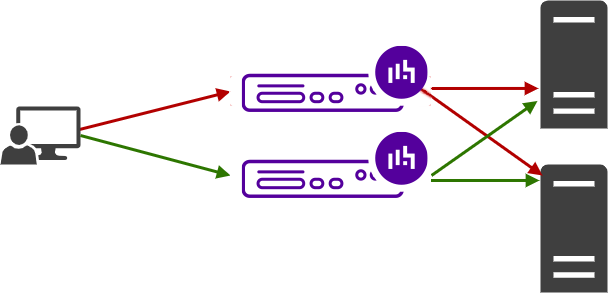
Having redundancy between your application servers and load balancers ensures near-continuous uptime. So, even though one appliance will help you scale out your backend servers, it won't help you completely avoid the vulnerability of a single point of failure. Hence why you need a pair - and buying a single load balancer is a false economy.
And if you want endless scalability, you can also load balance your load balancers!

Expecting growth? Get a load balancer that will always meet expectations

Related posts
Hardening HashiCorp Vault with load balancing for always-on security

What's the best cloud load balancer? AWS, Azure, GCP, Cloudflare, or a third-party alternative?

Architecting the perfect Christmas? A Highly Available light display!
How to load balance a MariaDB Galera Cluster for performance and HA using LVS & Ldirectord
HAProxy Enterprise Edition vs Progress Kemp LoadMaster: A no-fluff engineer comparison

Loadbalancer.org announces leadership transition and next phase of growth
ENVOY Proxy versus Loadbalancer.org: Why storage vendors need purpose-built load balancing for S3, NFS, and SMB

Architecting resilient object storage: Delivering multi-site capabilities for HPE with Loadbalancer.org GSLB