
Do you really need 5 different ways to back up a load balancer?
Published on •6 mins Last updated
Sometimes, having too many choices can lead to bad decisions. And yet everyone likes to have choices, don't they?
My gut instinct is that it makes sense to have only one backup and restore method. But let's explore this question a bit further by looking at the backup choices you have in the Loadbalancer Enterprise ADC.
1. Bare Metal Restore via USB stick, CD/ISO or PXE Network boot
💡 PRO TIP
Follow this procedure if you have a hardware load balancer appliance.
Lots of people still have a hardware appliance, and it's definitely a lot quicker and easier than being forced to do an RMA (i.e. return to the manufacturer under warranty and wait for a repair).
It's actually quite shocking that some vendors still refuse to support this method of restoring hardware that you have already paid for!
You can find the full details on how easy we make hardware ADC recovery for you in this blog: Updating your Loadbalancer.org hardware.
2. Full backup or snapshot from your hypervisor e.g. VMWare/HyperV/Xen
💡 PRO TIP
Follow this procedure for hypervisors.
Hang on, you mean I can just use my hypervisors usual snapshot/backup process for my ADC appliances?
Well, yes... but, you have a couple of things to be cautious about. Be careful running snapshots on busy production systems. When the Virtual Machine's memory state is captured in a snapshot, the snapshot takes longer to complete and network response might also slow. Which is probably a bad idea with a production load balancer! It can also effect the heartbeat in a high availability cluster.
The other gotcha is that a lot of vendors go to great lengths to stop you from doing this. Why? Because they are worried you might copy their software and not pay for additional licenses. Several vendors go to great lengths to detect subtle hardware changes, then force you to wait on the phone for hours to generate a new license key for the new snapshot.
Rest assured — Loadbalancer.org would never block you backing up your own software, we trust you.
3. Full backup file on remote secure storage
💡 PRO TIP
The standard operating procedure.
OK, so this probably should have been option number 1. This is the standard method, supported by all vendors. And you are definitely going to want to have several of these backup files securely stored in your own preferred location.
Obviously, the whole point of this file is to be able to recover your entire system should the building burn down and you have to start from scratch.
But yet again, why do some vendors make this difficult?
When you test the restoration process for this file you may get some nasty surprises. Most vendors don't include the license file. So you won't actually be able to get back up and running without phoning the vendors support desk! Some vendors don't include SSL certificates, or extra modules for WAF, GSLB etc. And what about all your custom rules and health checks? You'd definitely better check all of these things when you do a disaster recovery test.
💡 PRO TIP
An important note on HA pairs!
Oh, and one last thing — you always deploy ADCs in High Availability pairs, right? Do you need separate backup files for each one? And how do you restore both seamlessly?
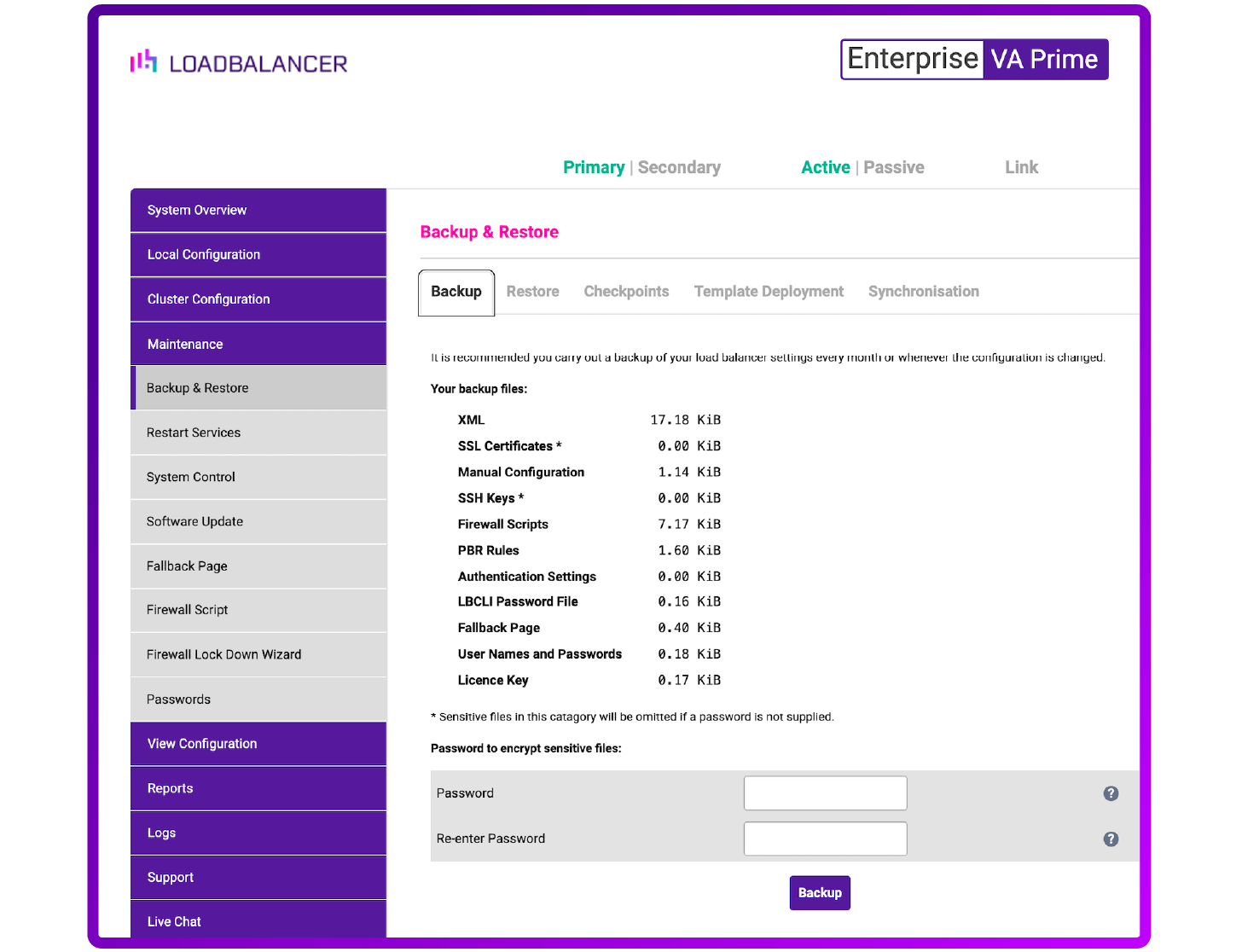
Loadbalancer.org includes ALL the files you need, including the license. And, yes, you will need to restore both the passive and active load balancers from different backup files.
But, to be brutally honest, all vendors struggle with these problems. Citrix probably has the best and most advanced solutions for zero downtime recovery.
But rest assured our mission here at load balancer is helping you achieve zero downtime (so we will redouble our efforts!).
4. Local checkpoint or snapshot on the ADC appliance itself
Obviously, this should not be your only backup! But local snapshots can be incredibly handy if you are performing a maintenance task, or configuration change and need a quick way of rolling back.
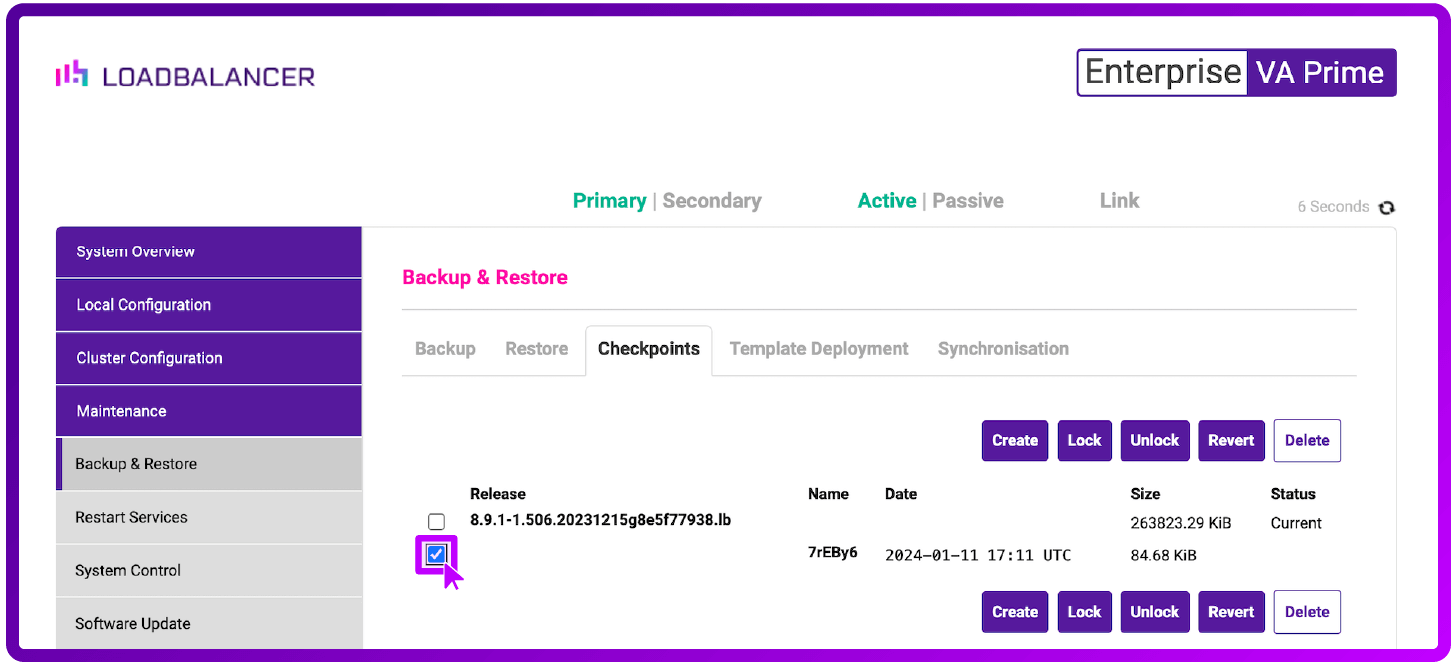
Some vendors support local storage of backup files, which is very similar to a snapshot. However, there is a big difference.
💡 PRO TIP
Important note on snapshots and backup files.
So why is a snapshot different from a full backup file...?
The reason we recently implemented snapshots on the Loadbalancer Enterprise product was to enable the smooth rollforward and rollback of both our online and offline software updates.
For example, if you rolled forward 3 or 4 software updates in one jump, and then encountered some problems, you could instantly jump back to the previous software version and configuration. So the snapshots not only include the usual backup files; they also include the full system files for each specific version of the product. We like to think that's quite a powerful feature. Especially as some vendors don't even support software updates, and some force you to upload full system images for specific versions. Oh, and you have to phone support to get access to the file in the first place, of course :-).
5. Full or partial system backups using Templates
Several vendors support the use of templates. They are usually used to help you deploy standard configurations for certain applications. For example, Kemp has some great Microsoft Exchange templated configurations.
Here at Loadbalancer.org we've extended the concept, so that you can export and modify your own templates. Which can contain not only the Virtual Server configurations, but also the backend configurations. This is especially useful if you were, for example, rolling out similar GSLB configurations to multiple data centers with hundreds of mirrored backend nodes.
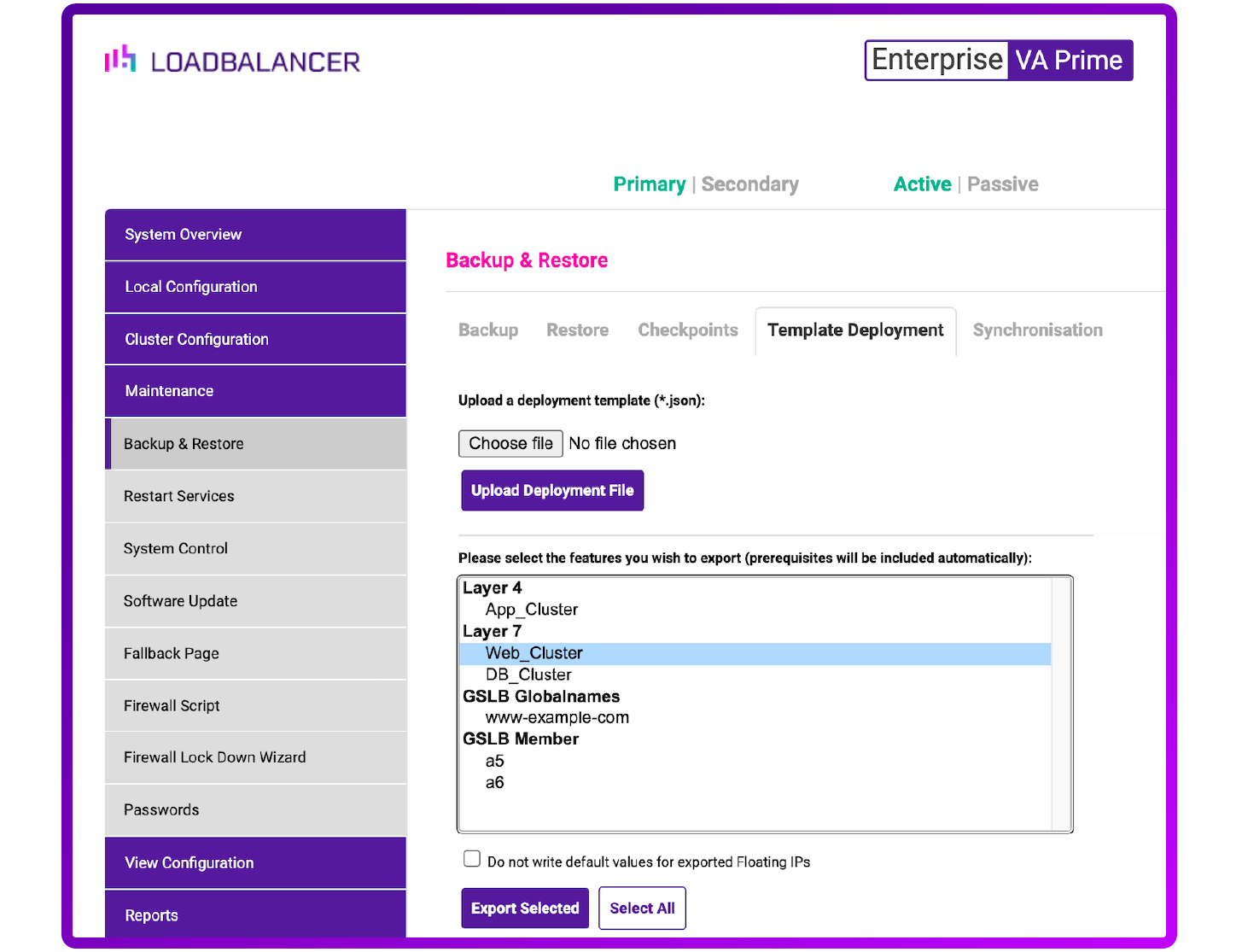
Templates don't have the base network configuration of the appliance, or the license file. We've got several aspects of the template system that we'd like to improve (like adding better support for MTLS certificates) but we'd like your feedback to see how we can improve the concept for your particular requirements.
💡 PRO TIP
Don't forget!
Let's not forget, that we don't really want to backup our load balancer — what we really want is to restore it!
You also want the flexibility to be able to use the right kind of backup, at the right time. You never know what is going to happen in the future, so exactly as the Scouts motto says, you should "Be prepared".
So bearing that in mind, I think the more backups you have, the better. But perhaps more importantly, you should thoroughly test your disaster recovery plan. What happens if you need to move everything to a different building or a new platform, and you need to do it in a hurry?
Here at Loadbalancer, we're 100% committed to our vision:
"A world where you never have to deal with the pain that downtime causes for you and your customers"
But, hey, we're not saying our product is perfect...
Which is why we're working hard on our cloud-based ADC Portal to make maintenance, backup and recovery as easy as possible. For ANY ADC appliance. Yes that's right, for F5, Citrix, and Kemp as well...
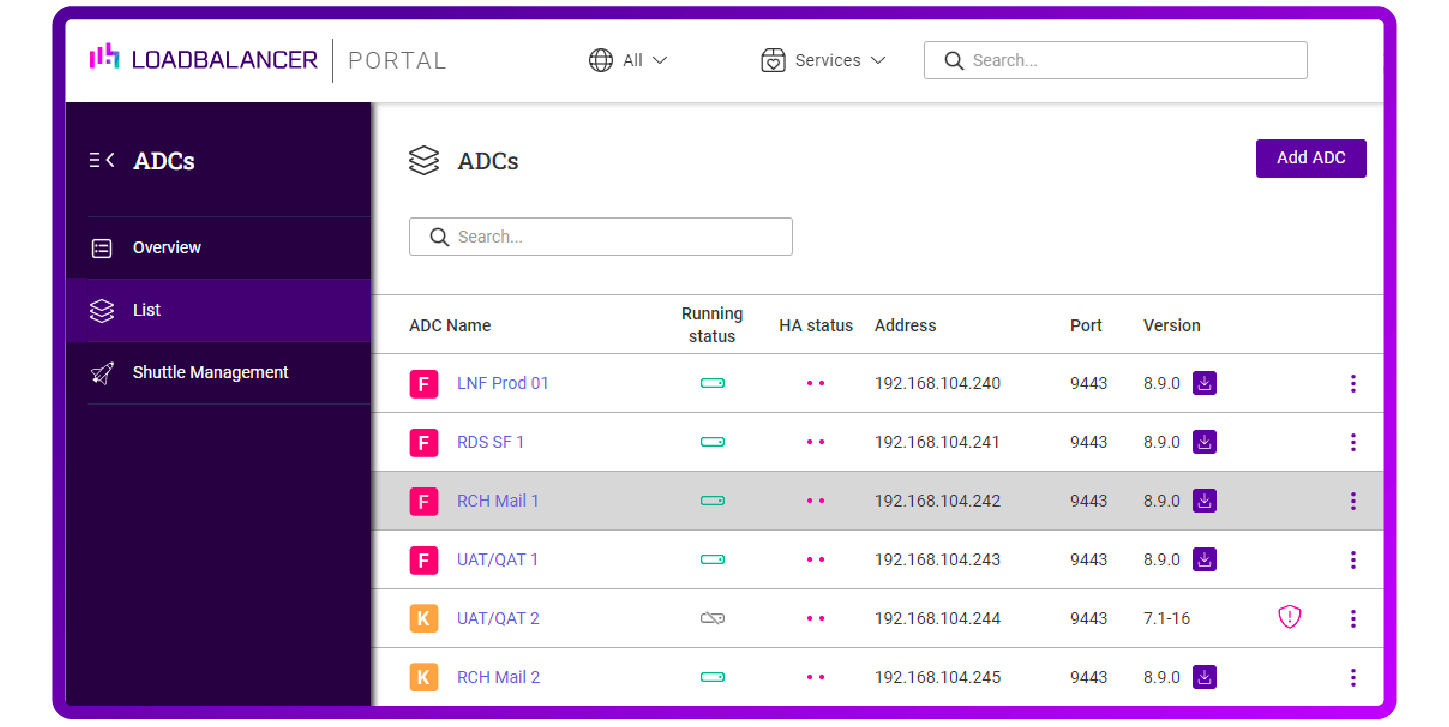
And we'd love your feedback on how we can make this even better, so please comment on this blog, or phone/email/chat — but please let us know!