HAProxy load balancer feedback agent check — We've Open Sourced our Windows service so you can extend it how you like.
Application Management Published on •7 mins Last updated
Wow, I just came to update this with the latest version and was shocked to notice the blog is almost 10 years old! — We keep finding new uses for our HAProxy Feedback Agent.. But, please let me know what you use it for in the comments section :-).
So what's a load balancer feedback agent check and why do I need one?
In general when you are load balancing a cluster you can evenly spread the connections through the cluster and you get pretty consistent and even load balancing. However with some applications such as RDS (Microsoft Terminal Servers), you might get very high load from just a few users doing heavy work. This in turn could result in slow performance for other users on the same server.
The solution to this problem is to use some kind of server load feedback agent check.
The Loadbalancer.org appliance has had an adaptive feedback agent for a while now. However with a LOT of help from Simon Horman (of UltraMonkey fame) — we've managed to integrate the functionality into the main open source branch of HAproxy.
We also thought it would be a good idea to open source our previous work on Ldirectord/LVS, make it compatible with HAProxy, and release our Windows service code under the GPL License.
UPDATE: The Loadbalancer.org feedback agent code is now fully supported in HAProxy 1.5-dev21.
And because it's in the mainline branch, all future versions as well.
You can find the latest documentation for the HAProxy agent check here.
How do I install the feedback agent on Windows?
Simply download the latest Windows Feedback Agent installation package here:
http://downloads.loadbalancer.org/agent/loadbalanceragent.msi (v4.6.0) [Updated 01/09/2022]
Upgrading to the new version will install a new generic configuration. If you have made changes to the default thresholds in the configuration file. Please make a copy of these. You can always contact Loadbalancer.org support for assistance before upgrading.
The feedback agent functionality is available in all versions of the Loadbalancer.org appliance software for both layer 4 (Ldirectord) and layer 7 (HAProxy).
Just downloaded and installed the msi file from the link above, accept all the usual security warnings. It's an almost silent install, once the progress bar disapears the agent is installed as a service and starts running with the default setting immediately.
you can find the client application in the start menu it's called "Feedback Agent Service Monitor". Or if you want the specific file location it's here:
C:\ProgramData\LoadBalancer.org\LoadBalancer\monitor.exe
The agent should already be responding to telnet on port 3333 (However, you may need to make an exception for that port in your Windows firewall).
Then make sure you modify your virtual server on the load balancer to poll the feedback agent:

Then on the Windows server client:
You can change the 'mode' setting to drain then 'apply settings and restart' and HAProxy will then set the weight to 0 and status to drain (blue) i.e.:
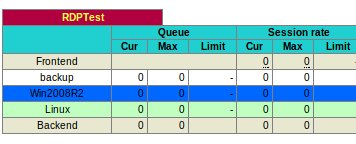
Or you can set the 'mode' to halt then 'apply settings and restart' and HAProxy will then immediately set the status to DOWN (yellow) i.e.:
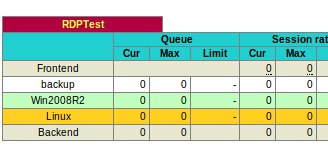
When the agent is running in normal mode it will report back the percentage idle of the system based on the settings in the feedback agent XML file:
C:\ProgramData\LoadBalancer.org\LoadBalancer\config.xml
<xml>
<Cpu>
<ImportanceFactor value="1" />
<ThresholdValue value="100" />
</Cpu>
<Ram>
<ImportanceFactor value="0" />
<ThresholdValue value="100" />
</Ram>
<TCPService>
<Name value="HTTP" />
<IPAddress value="*" />
<Port value="80" />
<MaxConnections value="0" />
<ImportanceFactor value="0" />
</TCPService>
<ReadAgentStatusFromConfig value="False" />
<ReadAgentStatusFromConfigInterval value="5" />
<AgentStatus value="Normal" />
<Interval value="10" />
</xml>
Notice that you can control both the importance of CPU & RAM utilization and also a threshold, so the following logic is used:
- If CPU importance = 0 then ignore, 0.5 means give 50% importance, 1 means 100% importance
- If RAM importance = 0 then ignore etc.
If ThresholdValue is reached on any monitor then immediately go into DRAIN mode (a value of 0 means no threshold is set).
This can be very useful if you have a small number of RDP sessions using a lot of RAM, simply set a ThresholdValue of 85, then as soon as memory crosses that threshold no new users will be sent to that server.
Otherwise to calculate the percentage idle reported by the agent would be to divide the utilization by the number of factors involved i.e.
If you are using two services then:
- utilization = utilization + cpuLoad * cpuImportance%;
- utilization = utilization + ramOccupied * ramImportance%;
- utilization = utilization / 2
So if importance was 1 for both cpu and ram you would only get 0% reported if both CPU and RAM were 100%. (actually it gets a bit weird if one is already reporting 0%, but lets not worry about that....
And if the importance is zero then ignore completely i.e.
- AS: utilization = utilization + cpuLoad * cpuImportance%;
- IF: utilization = utilization + ramOccupied * 0 (importance is zero so ignore)
- THEN: utilization = utilization (one service only so don't divide)
Also the final section TCPService effectively lets you load balance on number of established connections to your server, so you could balance based on the number of RDP connections to port 3389.
For this setting MaxConnections is important to specify as otherwise the agent will have no idea how to calculate the load i.e.
- utilization = MaxConnections / 100 * number of current connections * importance%
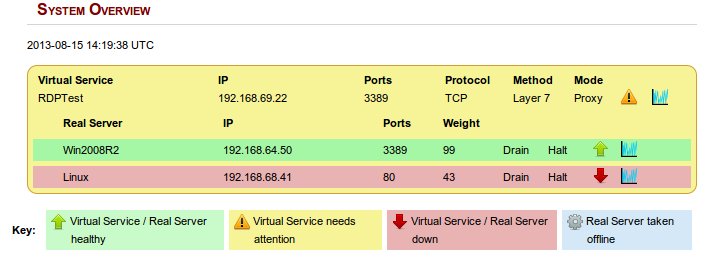
In the following screen shot from a Loadbalancer.org appliance you can see that the Win2008R2 server is healthy and 99% idle, whereas the Linux server was busy at 43% idle before the Linux agent was put into maintenance mode and the server taken out of the group.
Does that make sense? Have a play with the config file and let us know what you think....
The agent functionality is obviously not just for Windows users:
Lets look at an example of load balancing Microsoft RDS with HAProxy:
listen RDSTest
bind 192.168.69.22:3389
mode tcp
balance leastconn
persist rdp-cookie
server backup 127.0.0.1:9081 backup non-stick
tcp-request inspect-delay 5s
tcp-request content accept if RDP_COOKIE
timeout client 12h
timeout server 12h
option tcpka
option redispatch
option abortonclose
maxconn 40000
server Win2008R2 192.168.64.50:3389 weight 100 check agent-check agent-port 3333 inter 2000 rise 2 fall 3 minconn 0 maxconn 0 on-marked-down shutdown-sessions
The important bit agent-check agent-port 3333 tells HAProxy to constantly monitor each backend server in the cluster by doing a telnet to port 3333 and grabbing the response which will usually be a percentage idle value i.e.
- 80% - I am not very busy please increase my weight and send me more traffic
- 10% - I'm busy please decrease my weight and stop sending me so much traffic
- drain - Set the weight to 0 and gradually drain the traffic from this server for maintenance
- maint - Set the weight to 0 and immediately stop the traffic from this server for maintenance
- down - Stop all traffic immediately, kill this backend server
- up - Enable traffic immediately, if no existing state conflicts.
- up ready 20% - Force HAProxy to bring the server up and set weight to 20% (irrespective of how it was taken down, reseting all health states)
If you have a Linux backend you could create a simple service calling the following script:
#!/bin/bash
# This outputs a 1 second average CPU idle
LOAD=$(/usr/bin/vmstat 1 2 | /usr/bin/tail -1 | /usr/bin/awk '{ print $15 }' | /usr/bin/tee)
echo "$LOAD%"
Place the script into /usr/bin and call it
/usr/bin/lb-feedback.sh
Make sure that you make the script executable
chmod +x /usr/bin/lb-feedback.sh
Insert this line into /etc/services
lb-feedback 3333/tcp # loadbalancer.org feedback daemon
Now create the following file called /etc/xinetd.d/lb-feedback
# default: on
# description: lb-feedback socket server
service lb-feedback
{
port = 3333
socket_type = stream
flags = REUSE
wait = no
user = nobody
server = /usr/bin/lb-feedback.sh
log_on_success += USERID
log_on_failure += USERID
disable = no
}
Then change permissions and restart xinetd:
chmod 644 /etc/xinetd.d/lb-feedback
/etc/init.d/xinetd restart
You can now test this service by using telnet:
telnet 127.0.0.1 3333
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
95%
Connection closed by foreign host.
Where do I find the source code?
Our Windows feedback agent has recently undergone a complete rewrite in a language called GO. We felt that our previous implementation of the feedback agent was feeling a bit dated, requiring an older version of the .net framework and was becoming a pain to maintain. With this new version, the agent technically allows for cross-platform compatibility, improves performance as GO is a compiled language, and lastly is so much easier to support. A more detailed explanation of the benefits and setbacks of getting thus far will be explained in a future blog.
Our GO feedback agent check is open source and can be found on Github here.